One-shot Implicit Animatable Avatars with Model-based Priors


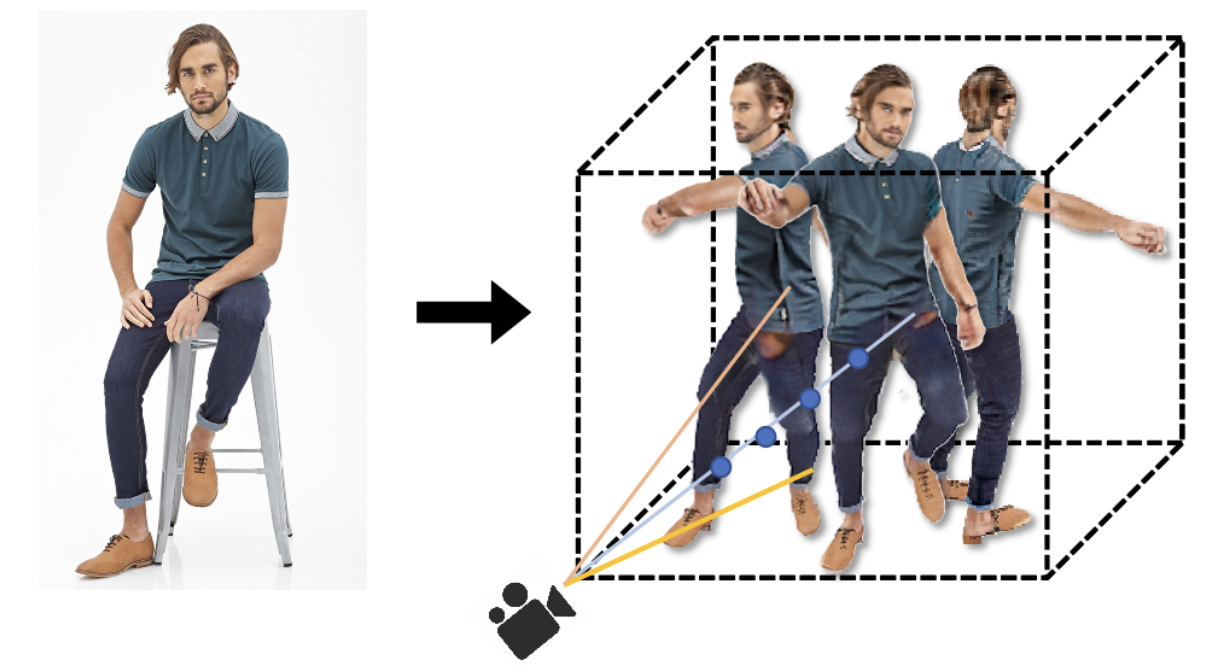
Existing neural rendering methods for creating human avatars typically either require dense input signals such as video or multi-view images, or leverage a learned prior from large-scale specific 3D human datasets such that reconstruction can be performed with sparse-view inputs. Most of these methods fail to achieve realistic reconstruction when only a single image is available. To enable the data-efficient creation of realistic animatable 3D humans, we propose ELICIT, a novel method for learning human-specific neural radiance fields from a single image. Inspired by the fact that humans can easily reconstruct the body geometry and infer the full-body clothing from a single image, we leverage two priors in ELICIT: 3D geometry prior and visual semantic prior. Specifically, ELICIT introduces the 3D body shape geometry prior from a skinned vertex-based template model (i.e., SMPL) and implements the visual clothing semantic prior with the CLIP-based pre-trained models. Both priors are used to jointly guide the optimization for creating plausible content in the invisible areas. In order to further improve visual details, we propose a segmentation-based sampling strategy that locally refines different parts of the avatar.Comprehensive evaluations on multiple popular benchmarks, including ZJU-MoCAP, Human3.6M, and DeepFashion, show that ELICIT has outperformed current state-of-the-art avatar creation methods when only a single image is available. Code will be public for reseach purpose at https://github.com/huangyangyi/ELICIT
| Author(s): | Huang, Yangyi* and Yi, Hongwei* and Liu, Weiyang and Wang, Haofan and Wu, Boxi and Wang, Wenxiao and Lin, Binbin and Zhang, Debing and Cai, Deng |
| Book Title: | Proc. International Conference on Computer Vision (ICCV) |
| Pages: | 8940--8951 |
| Year: | 2023 |
| Month: | October |
| Bibtex Type: | Conference Paper (inproceedings) |
| DOI: | 10.1109/ICCV51070.2023.00824 |
| Event Name: | International Conference on Computer Vision 2023 |
| Event Place: | Paris, France |
| State: | Published |
| Electronic Archiving: | grant_archive |
| Note: | *equal contribution |
| Links: | |
BibTex
@inproceedings{Huangetal23,
title = {One-shot Implicit Animatable Avatars with Model-based Priors},
booktitle = {Proc. International Conference on Computer Vision (ICCV)},
abstract = {Existing neural rendering methods for creating human avatars typically either require dense input signals such as video or multi-view images, or leverage a learned prior from large-scale specific 3D human datasets such that reconstruction can be performed with sparse-view inputs. Most of these methods fail to achieve realistic reconstruction when only a single image is available. To enable the data-efficient creation of realistic animatable 3D humans, we propose ELICIT, a novel method for learning human-specific neural radiance fields from a single image. Inspired by the fact that humans can easily reconstruct the body geometry and infer the full-body clothing from a single image, we leverage two priors in ELICIT: 3D geometry prior and visual semantic prior. Specifically, ELICIT introduces the 3D body shape geometry prior from a skinned vertex-based template model (i.e., SMPL) and implements the visual clothing semantic prior with the CLIP-based pre-trained models. Both priors are used to jointly guide the optimization for creating plausible content in the invisible areas. In order to further improve visual details, we propose a segmentation-based sampling strategy that locally refines different parts of the avatar.Comprehensive evaluations on multiple popular benchmarks, including ZJU-MoCAP, Human3.6M, and DeepFashion, show that ELICIT has outperformed current state-of-the-art avatar creation methods when only a single image is available. Code will be public for reseach purpose at https://github.com/huangyangyi/ELICIT},
pages = {8940--8951},
month = oct,
year = {2023},
note = {*equal contribution},
slug = {huangetal23},
author = {Huang, Yangyi* and Yi, Hongwei* and Liu, Weiyang and Wang, Haofan and Wu, Boxi and Wang, Wenxiao and Lin, Binbin and Zhang, Debing and Cai, Deng},
month_numeric = {10}
}