
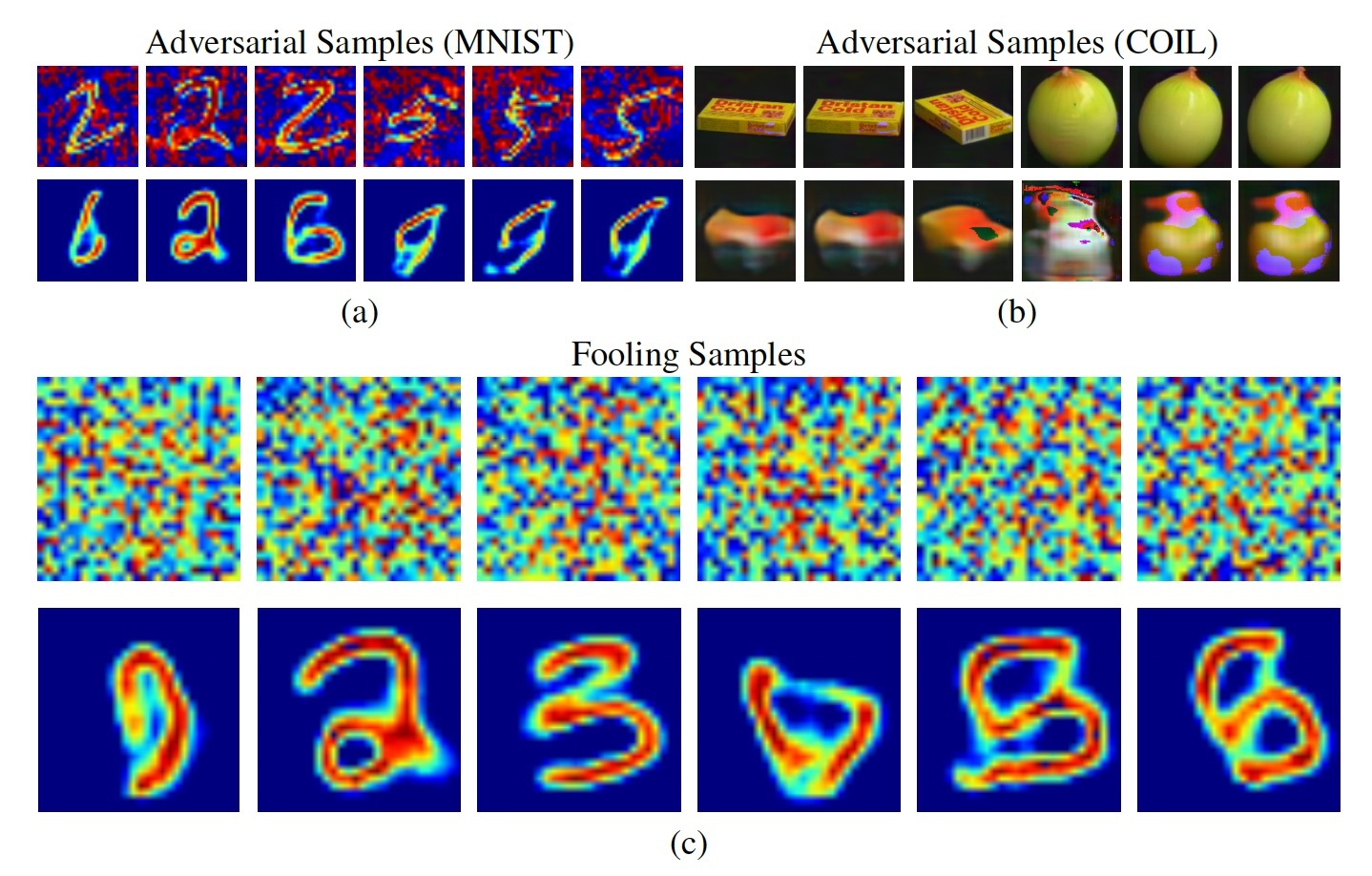
This thesis studies controllability of generative models (specifically VAEs and GANs) applied primarily to images. We improve 1. generation quality, by removing the arbitrary prior assumptions, 2. classification by suitably choosing the latent space distribution, and 3. inference performance by optimizing the generative and inference objective simultaneously. Variational autoencoders (VAEs) are an incredibly useful tool as they can be used as a backbone for a variety of machine learning tasks e.g., semi-supervised learning, representation learning, unsupervised learning, etc. However, the generated samples are overly smooth and this limits their practical usage tremendously. There are two leading hypotheses to explain this: 1. bad likelihood model and 2. overly simplistic prior. We investigate these by designing a deterministic yet samplable autoencoder named Regularized Autoencoders (RAE). This redesign helps us enforce arbitrary priors over the latent distribution of a VAE addressing hypothesis (1) above. This leads us to conclude that a poor likelihood model is the predominant factor that makes VAEs blurry. Furthermore, we show that combining generative (e.g., VAE objective) and discriminative objectives (e.g., classification objective) improve performance of both. Specifically, We use a special case of an RAE to build a classifier that offers robustness against adversarial attack. Conditional generative models have the potential to revolutionize the animation industry, among others. However, to do so, the two key requirements are, 1. they must be of high quality (i.e., generate high-resolution images) and 2. must follow their conditioning (i.e., generate images that have the properties specified by the condition). We exploit pixel-localized correlation between the conditioning variable and generated image to ensure strong association between the two and thereby gain precise control over the generated content. We further show that closing the generation-inference loop (training them together) in latent variable models benefits both the generation and the inference component. This opens up the possibility to train an inference and a generative model simultaneously in one unified framework, in the fully or semi supervised setting. With the proposed approach, one can build a robust classifier by introducing the marginal likelihood of a data point, removing arbitrary assumptions about the prior distribution, mitigating posterior-prior distribution mismatch and completing the generation inference loop. In this thesis, we study real-life implications of each of the themes using various image classification and generation frameworks.
| Author(s): | Partha Ghosh |
| Year: | 2023 |
| Month: | May |
| Bibtex Type: | Ph.D. Thesis (phdthesis) |
| Degree Type: | PhD |
| DOI: | http://dx.doi.org/10.15496/publikation-82895 |
| Institution: | University of Tübingen |
| State: | Published |
| Links: | |
| Attachments: | |
BibTex
@phdthesis{ParthaThesis2023,
title = {Reining in the Deep Generative Models},
abstract = {This thesis studies controllability of generative models (specifically VAEs and GANs) applied
primarily to images. We improve 1. generation quality, by removing the arbitrary prior assumptions,
2. classification by suitably choosing the latent space distribution, and 3. inference
performance by optimizing the generative and inference objective simultaneously.
Variational autoencoders (VAEs) are an incredibly useful tool as they can be used as a backbone
for a variety of machine learning tasks e.g., semi-supervised learning, representation
learning, unsupervised learning, etc. However, the generated samples are overly smooth and
this limits their practical usage tremendously. There are two leading hypotheses to explain this:
1. bad likelihood model and 2. overly simplistic prior. We investigate these by designing a deterministic
yet samplable autoencoder named Regularized Autoencoders (RAE). This redesign
helps us enforce arbitrary priors over the latent distribution of a VAE addressing hypothesis
(1) above. This leads us to conclude that a poor likelihood model is the predominant factor
that makes VAEs blurry. Furthermore, we show that combining generative (e.g., VAE objective)
and discriminative objectives (e.g., classification objective) improve performance of both.
Specifically, We use a special case of an RAE to build a classifier that offers robustness against
adversarial attack.
Conditional generative models have the potential to revolutionize the animation industry,
among others. However, to do so, the two key requirements are, 1. they must be of high quality
(i.e., generate high-resolution images) and 2. must follow their conditioning (i.e., generate images
that have the properties specified by the condition). We exploit pixel-localized correlation
between the conditioning variable and generated image to ensure strong association between
the two and thereby gain precise control over the generated content. We further show that
closing the generation-inference loop (training them together) in latent variable models benefits
both the generation and the inference component. This opens up the possibility to train an
inference and a generative model simultaneously in one unified framework, in the fully or semi
supervised setting.
With the proposed approach, one can build a robust classifier by introducing the marginal
likelihood of a data point, removing arbitrary assumptions about the prior distribution, mitigating
posterior-prior distribution mismatch and completing the generation inference loop. In this
thesis, we study real-life implications of each of the themes using various image classification
and generation frameworks.},
degree_type = {PhD},
institution = {University of Tübingen},
month = may,
year = {2023},
slug = {parthathesis2023},
author = {Ghosh, Partha},
month_numeric = {5}
}