Autonomous Robotic Manipulation
Modeling Top-Down Saliency for Visual Object Search
Interactive Perception
State Estimation and Sensor Fusion for the Control of Legged Robots
Probabilistic Object and Manipulator Tracking
Global Object Shape Reconstruction by Fusing Visual and Tactile Data
Robot Arm Pose Estimation as a Learning Problem
Learning to Grasp from Big Data
Gaussian Filtering as Variational Inference
Template-Based Learning of Model Free Grasping
Associative Skill Memories
Real-Time Perception meets Reactive Motion Generation
Autonomous Robotic Manipulation
Learning Coupling Terms of Movement Primitives
State Estimation and Sensor Fusion for the Control of Legged Robots
Inverse Optimal Control
Motion Optimization
Optimal Control for Legged Robots
Movement Representation for Reactive Behavior
Associative Skill Memories
Real-Time Perception meets Reactive Motion Generation
Efficient volumetric inference with OctNet
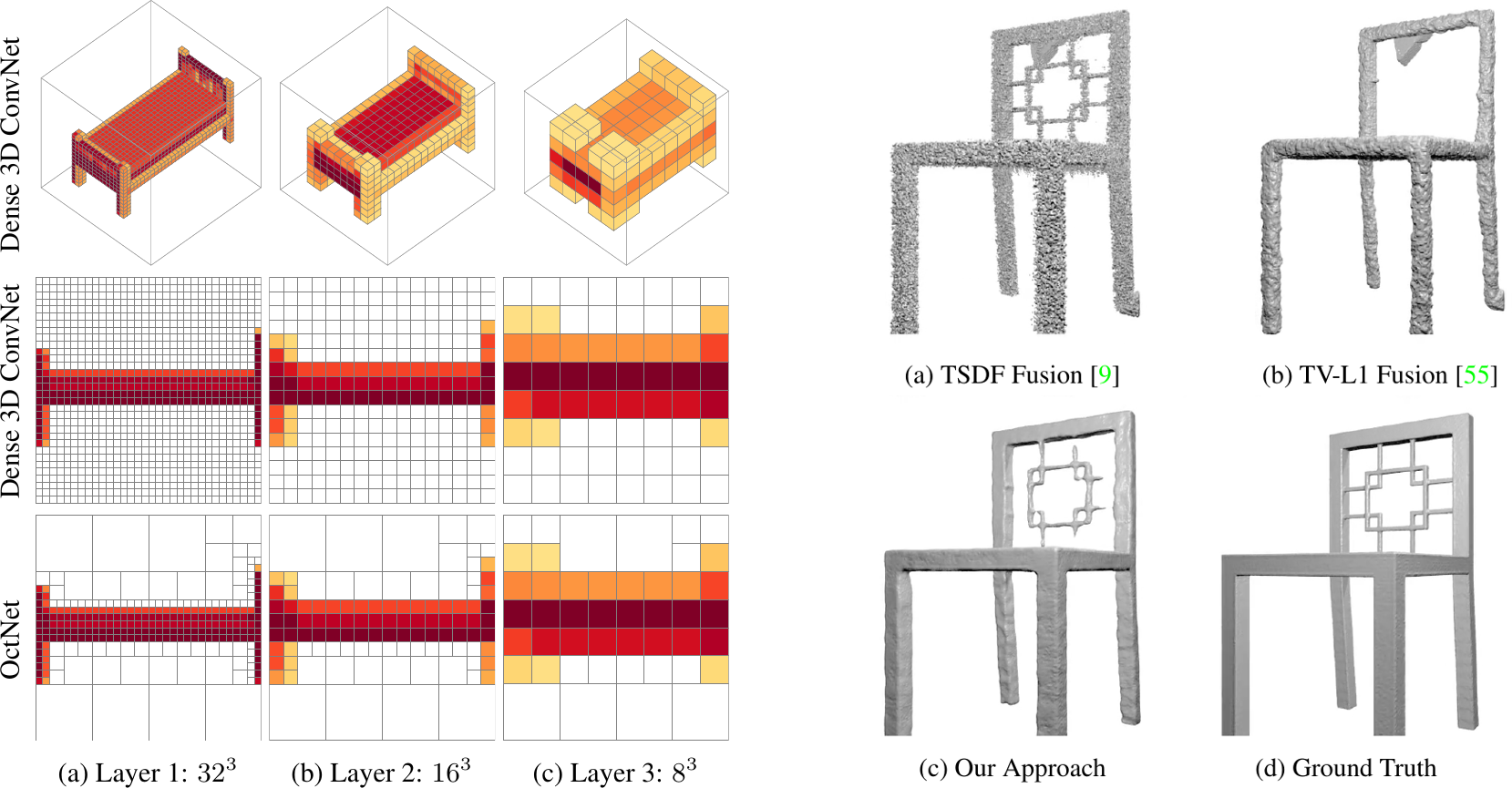
3D deep learning techniques are notoriously memory-hungry, due to the high-dimensional input and output spaces. However, for most applications, not all areas of space are equally informative or important. In order to allow deep learning techniques to scale to spatial resolutions of 256³ and beyond, we have developed the OctNet framework [![]() ].
].
In contrast to existing models, our representation enables 3D convolutional networks which are both deep and high resolution. The data-adaptive representation using unbalanced octrees allows us to focus memory allocation and computations to the relevant dense regions.
With OctNetFusion [![]() ], we present a learning-based approach to depth fusion, i.e. to dense 3D reconstruction from multiple depth images. We present a novel 3D CNN architecture that learns to predict an implicit surface representation from the input depth maps, and is additionally able to infer the structure of the octrees representing the objects at inference time.
], we present a learning-based approach to depth fusion, i.e. to dense 3D reconstruction from multiple depth images. We present a novel 3D CNN architecture that learns to predict an implicit surface representation from the input depth maps, and is additionally able to infer the structure of the octrees representing the objects at inference time.
Members



Publications