Depth Fusion using Successive Reprojections
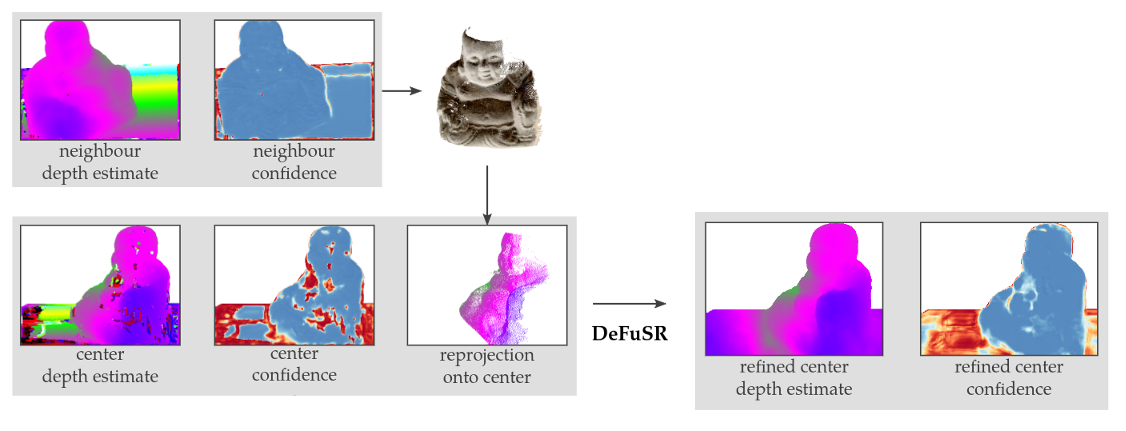
Given a set of input views, multi-view stereopsis techniques estimate depth maps to represent the 3D reconstruction of the scene; these are fused into a single, consistent, reconstruction -- most often a point cloud. In this work we propose to learn an auto-regressive depth refinement directly from data. While deep learning has improved the accuracy and speed of depth estimation significantly, learned MVS techniques remain limited to the planesweeping paradigm. We refine a set of input depth maps by successively reprojecting information from neighbouring views to leverage multi-view constraints. Compared to learning-based volumetric fusion techniques, an image-based representation allows significantly more detailed reconstructions; compared to traditional point-based techniques, our method learns noise suppression and surface completion in a data-driven fashion. Due to the limited availability of high-quality reconstruction datasets with ground truth, we introduce two novel synthetic datasets to (pre-)train our network. Our approach is able to improve both the output depth maps and the reconstructed point cloud, for both learned and traditional depth estimation front-ends, on both synthetic and real data.
Github for source code: https://github.com/simon-donne/defusr
Paper: http://www.cvlibs.net/publications/Donne2019CVPR.pdf
Poster: http://www.cvlibs.net/publications/Donne2019CVPR_poster.pdf
Supplementary: http://www.cvlibs.net/publications/Donne2019CVPR_supplementary.pdf
Data/datasets:
Generated FlyingThingsMVS, quarterHD: flying_things_MVS_0.25.tar.gz
Backgrounds for this dataset (required by the generation script): flying_backgrounds.tar.gz
Generated UnrealDTU dataset, drop-in for DTU: unrealDTU.tar.gz
Generated ground truth depth maps and auxiliary files for DTU: DTU_extension.tar.gz
Manual capture for the test on real data in the paper: manual_capture_set.tar.gz
Pretrained models for testing: models.zip
Video
Members

