New Optimizers for Foundation Models
We aim to advance the training speed of large language models through novel optimizers. Supported by theoretical insights into neural landscapes, our work bridges foundational research with practical advancements, addressing key challenges in training efficiency and scalability for foundation models in several application domains.
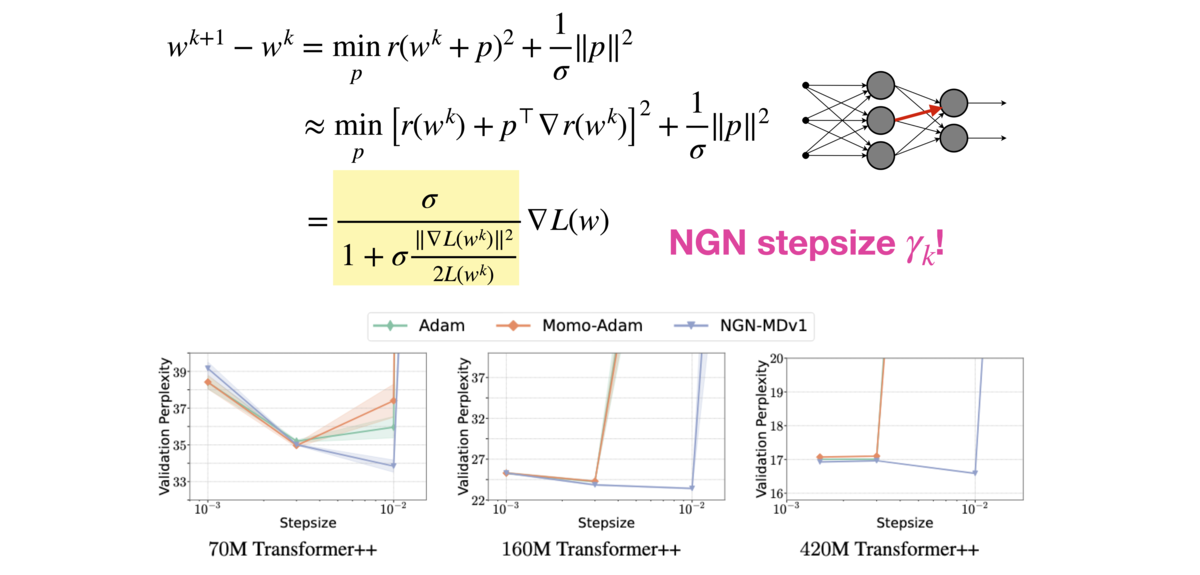
Our NGN optimizer[![]() ], rooted in a novel expansion technique that guarantees strong theoretical guarantees, showed promise in vision and text applications at scale, surpassing strong Adam baselines in networks at the scale of billions of parameters. Beyond practical algorithmic advancements such as NGN, the group engages in foundational research, exploring the geometric properties of neural network loss functions [
], rooted in a novel expansion technique that guarantees strong theoretical guarantees, showed promise in vision and text applications at scale, surpassing strong Adam baselines in networks at the scale of billions of parameters. Beyond practical algorithmic advancements such as NGN, the group engages in foundational research, exploring the geometric properties of neural network loss functions [![]() ], the complexities of nested min-max problems [
], the complexities of nested min-max problems [![]() ], and dynamics in convex settings, including acceleration [
], and dynamics in convex settings, including acceleration [![]() ] and limit cycle phenomena [
] and limit cycle phenomena [![]() ].
].
We continuously seek to develop and evaluate new optimization algorithms tailored for foundation models, such as large language models, to improve training efficiency, memory usage, and performance. Current solutions, including the widely used Adam optimizer, face challenges like instability and sensitivity to hyperparameters. By advancing our theoretical understanding of adaptive methods and rigorously testing these innovations at scale, the project aims to address critical bottlenecks in training large models. Outcomes include publicly available code, detailed findings reports, and benchmarks that provide valuable action items for academic and industry practitioners.