Comparative Vision Science
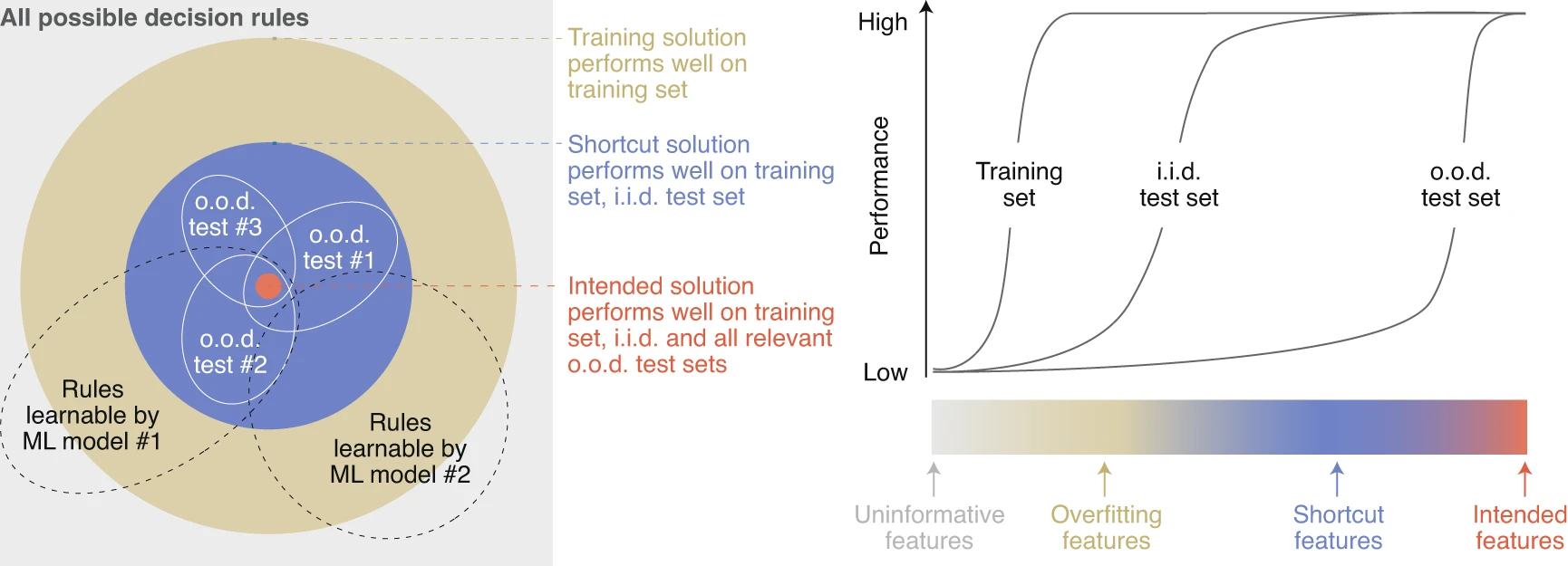
Machine vision systems do not perceive the world like humans. But how exactly do they differ? It is easy to identify failure cases in machine vision systems, such as their susceptibility to small, targeted image perturbations. In a 2020 perspective article in Nature Machine Intelligence [![]() ], we argue that a root cause of this gap is the reliance of machines on statistical shortcuts in the data. In other words, machine vision systems detect patterns in the data that are largely ignored by humans but carry predictive value for the task the system is trained on. But what exactly are these patterns and shortcuts? In some cases, these shortcuts can be revealed, as we have demonstrated through a long line of behavioral experiments involving both machines and human participants in well-controlled psychophysics studies [
], we argue that a root cause of this gap is the reliance of machines on statistical shortcuts in the data. In other words, machine vision systems detect patterns in the data that are largely ignored by humans but carry predictive value for the task the system is trained on. But what exactly are these patterns and shortcuts? In some cases, these shortcuts can be revealed, as we have demonstrated through a long line of behavioral experiments involving both machines and human participants in well-controlled psychophysics studies [![]() ]. In these experiments, we focus on out-of-distribution (OOD) scenarios designed to test which rules and features machines rely on for perception.
]. In these experiments, we focus on out-of-distribution (OOD) scenarios designed to test which rules and features machines rely on for perception.
Our work has revealed several striking differences between human and machine vision. For instance, machines rely heavily on texture rather than shape (as humans do) to classify objects [![]() ], disregard object-part relationships [
], disregard object-part relationships [![]() ], and exhibit decision-making patterns that are remarkably consistent across architectures and training methods but distinct from human behavior [
], and exhibit decision-making patterns that are remarkably consistent across architectures and training methods but distinct from human behavior [![]() ]. These insights highlight the limitations of machine vision systems, which often mirror "bag-of-feature" approaches from pre-deep learning eras.
]. These insights highlight the limitations of machine vision systems, which often mirror "bag-of-feature" approaches from pre-deep learning eras.
The rise of foundation models has challenged traditional notions of out-of-distribution (OOD) generalization. Their training on vast, diverse datasets has blurred the boundaries of OOD samples. In [![]() ], we analyzed zero-shot performance in visual foundation models like CLIP, probing how train-test similarity affects their behavior. Surprisingly, OOD accuracy was largely independent of visual similarity to training data, suggesting these models do not merely retrieve similar examples to solve test cases. However, in [
], we analyzed zero-shot performance in visual foundation models like CLIP, probing how train-test similarity affects their behavior. Surprisingly, OOD accuracy was largely independent of visual similarity to training data, suggesting these models do not merely retrieve similar examples to solve test cases. However, in [![]() ], we trained transformers on controlled domains (e.g., natural images, sketches) and found that OOD robustness remains limited without sufficient domain-relevant data, even at scale. This highlights a persistent gap between human and machine vision: foundation models do not rely solely on similar examples, yet they still require exposure to the right training domains to generalize effectively.
], we trained transformers on controlled domains (e.g., natural images, sketches) and found that OOD robustness remains limited without sufficient domain-relevant data, even at scale. This highlights a persistent gap between human and machine vision: foundation models do not rely solely on similar examples, yet they still require exposure to the right training domains to generalize effectively.