Foundations of Machine Learning
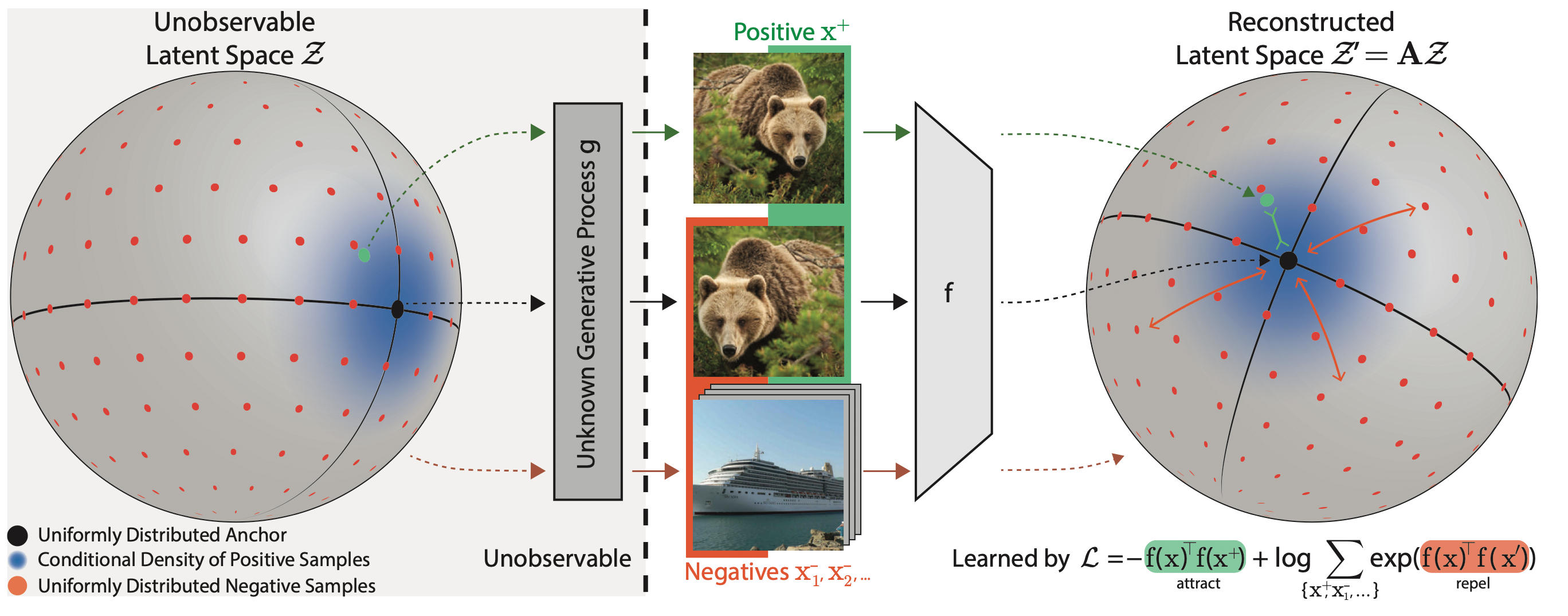
Within the field of theoretical machine learning, we are aiming to identify and overcome the root causes that limit the visual reasoning abilities of modern machine learning models. Our main tool is identifiability theory. Identifiability here refers to determining whether the hidden generating process underlying the observed data can be recovered. Our work [![]() ] was the first to realize that popular and empirically successful self-supervised contrastive learning techniques can provably uncover the true generative factors underlying a dataset. Since then, we extended this analysis to show that contrastive learning provably isolates content from style [
] was the first to realize that popular and empirically successful self-supervised contrastive learning techniques can provably uncover the true generative factors underlying a dataset. Since then, we extended this analysis to show that contrastive learning provably isolates content from style [![]() ] and that InfoNCE can be generalized to cover more realistic assumptions about the data generating process~[
] and that InfoNCE can be generalized to cover more realistic assumptions about the data generating process~[![]() ]. We also extended these results towards a more unified framework for both representation and causal structure learning under the lens of exchangeable (but not IID) data~[
]. We also extended these results towards a more unified framework for both representation and causal structure learning under the lens of exchangeable (but not IID) data~[![]() ] and causal discovery [
] and causal discovery [![]() ].
].
We now focus on understanding generalization. While generalization and rule extraction are central to machine learning, we still lack the theoretical and methodological tools to systematically explain how and when models generalize beyond statistical patterns to truly out-of-distribution (OOD) data.
We found that compositional generalization is not only a key aspect of human visual perception—one that current models struggle with [![]() ]—but also a property that can be rigorously formalized within identifiability theory. To this end, we first established an identifiability framework for structured, object-centric representation learning [
]—but also a property that can be rigorously formalized within identifiability theory. To this end, we first established an identifiability framework for structured, object-centric representation learning [![]() ] and derived compositional generalization conditions from first principles [
] and derived compositional generalization conditions from first principles [![]() ]. Building on these insights, we developed a practical theory of compositional generalization for object-centric learning [
]. Building on these insights, we developed a practical theory of compositional generalization for object-centric learning [![]() ].
].
While this work initially focused on relatively simple object compositions, we have since extended it to a unified principle for learning compositional abstractions that captures complex object-object interactions. This new framework performs on par with or better than state-of-the-art self-supervised object-centric learning algorithms~[![]() ].
].
Beyond vision models, we argue for a similar shift in perspective in large language models (LLMs)~[]. Our findings show that statistical learning theory alone cannot fully explain key LLM capabilities such as zero-shot rule extrapolation, in-context learning, and fine-tunability, further underscoring the need for a deeper theoretical foundation.