Training on the Test Task Confounds Evaluation and Emergence
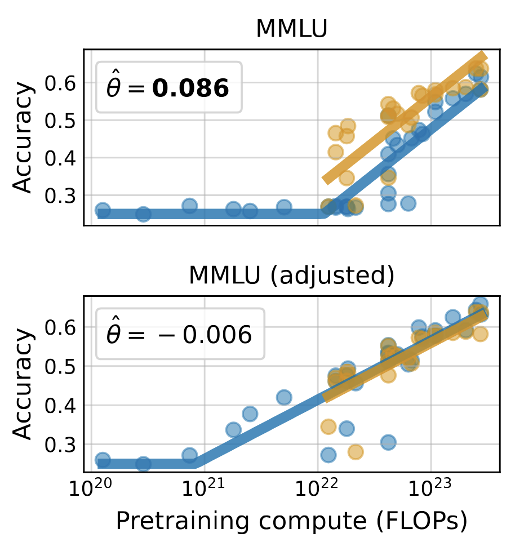
Top panel: Model accuracy on the MMLU benchmark as a function of pretraining compute, newer models (orange), older models (blue). Newer models appear to be better at utilizing compute. Also, high accuracy on MMLU appears to be emergent. Bottom panel: After adjusting for training on the test task, new and old models have the same scaling law. Moreover, accuracy picks up at much smaller model scale.
Benchmarking works best if all models have the same training data. Model builders today optimize training data mixes with the test task in mind, leading to confounded evaluations. We call the problem training on the test task and propose a simple adjustment that mitigates the problem..