2024
ps
Xiu, Y., Liu, Z., Tzionas, D., Black, M. J.
PuzzleAvatar: Assembling 3D Avatars from Personal Albums
ACM Transactions on Graphics, 43(6), ACM, December 2024 (article) To be published

ps
Ye, C., Qiu, L., Gu, X., Zuo, Q., Wu, Y., Dong, Z., Bo, L., Xiu, Y., Han, X.
StableNormal: Reducing Diffusion Variance for Stable and Sharp Normal
ACM Transactions on Graphics, 43(6), ACM, December 2024 (article) To be published
OS Lab
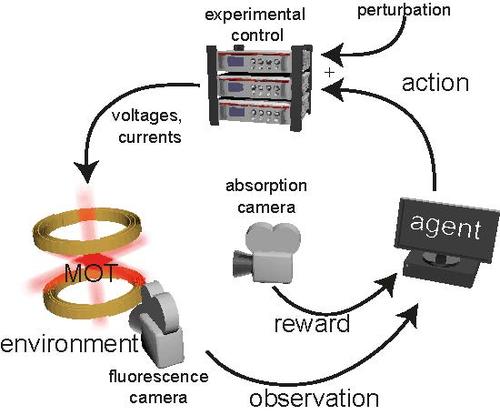
Reinschmidt, M., Fortágh, J., Günther, A., Volchkov, V.
Reinforcement learning in cold atom experiments
nature communications, 15:8532, October 2024 (article)

rm
Yoder, Z., Rumley, E., Schmidt, I., Rothemund, P., Keplinger, C.
Hexagonal electrohydraulic modules for rapidly reconfigurable high-speed robots
Science Robotics, 9, September 2024 (article)
hi
ei
OS Lab
zwe-sw
Cao, C. G. L., Javot, B., Bhattarai, S., Bierig, K., Oreshnikov, I., Volchkov, V. V.
Fiber-Optic Shape Sensing Using Neural Networks Operating on Multispecklegrams
IEEE Sensors Journal, 24(17):27532-27540, September 2024 (article)
ps
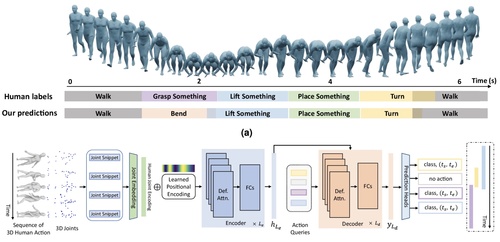
Sun, J., Huang, L., Hongsong Wang, C. Z. J. Q., Islam, M. T., Xie, E., Zhou, B., Xing, L., Chandrasekaran, A., Black, M. J.
Localization and recognition of human action in 3D using transformers
Nature Communications Engineering , 13(125), September 2024 (article)
hi
rm
Sanchez-Tamayo, N., Yoder, Z., Rothemund, P., Ballardini, G., Keplinger, C., Kuchenbecker, K. J.
Cutaneous Electrohydraulic (CUTE) Wearable Devices for Pleasant Broad-Bandwidth Haptic Cues
Advanced Science, (2402461):1-14, September 2024 (article)

rm
Buchner, T. J. K., Fukushima, T., Kazemipour, A., Gravert, S., Prairie, M., Romanescu, P., Arm, P., Zhang, Y., Wang, X., Zhang, S. L., Walter, J., Keplinger, C., Katzschmann, R. K.
Electrohydraulic Musculoskeletal Robotic Leg for Agile, Adaptive, yet Energy-Efficient Locomotion
Nature Communications, 15(1), September 2024 (article)

hi
Tashiro, N., Faulkner, R., Melnyk, S., Rodriguez, T. R., Javot, B., Tahouni, Y., Cheng, T., Wood, D., Menges, A., Kuchenbecker, K. J.
Building Instructions You Can Feel: Edge-Changing Haptic Devices for Digitally Guided Construction
ACM Transactions on Computer-Human Interaction, September 2024 (article) Accepted
ps
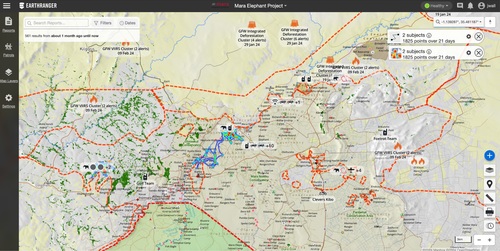
Wall, J., Lefcourt, J., Jones, C., Doehring, C., O’Neill, D., Schneider, D., Steward, J., Krautwurst, J., Wong, T., Jones, B., Goodfellow, K., Schmitt, T., Gobush, K., Douglas-Hamilton, I., Pope, F., Schmidt, E., Palmer, J., Stokes, E., Reid, A., Elbroch, M. L., Kulits, P., Villeneuve, C., Matsanza, V., Clinning, G., Oort, J. V., Denninger-Snyder, K., Daati, A. P., Gold, W., Cunliffe, S., Craig, B., Cork, B., Burden, G., Goss, M., Hahn, N., Carroll, S., Gitonga, E., Rao, R., Stabach, J., Broin, F. D., Omondi, P., Wittemyer, G.
EarthRanger: An Open-Source Platform for Ecosystem Monitoring, Research, and Management
Methods in Ecology and Evolution, 13, British Ecological Society, September 2024 (article)
ei
Bizeul, A., Schölkopf, B., Allen, C.
A Probabilistic Model behind Self-Supervised Learning
Transactions on Machine Learning Research, September 2024 (article) To be published
sf
Hakim, R., Stoica, A., Papadimitriou, C. H., Yannakakis, M.
The Fairness-Quality Trade-off in Clustering
arXiv preprint arXiv:2408.10002, September 2024 (article)
hi
Sharon, Y., Nevo, T., Naftalovich, D., Bahar, L., Refaely, Y., Nisky, I.
Augmenting Robot-Assisted Pattern Cutting With Periodic Perturbations – Can We Make Dry Lab Training More Realistic?
IEEE Transactions on Biomedical Engineering, August 2024 (article)
ps
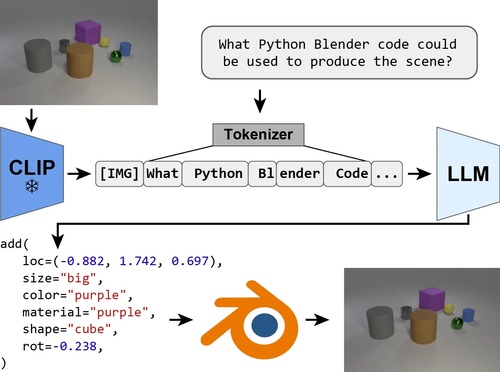
Kulits, P., Feng, H., Liu, W., Abrevaya, V., Black, M. J.
Re-Thinking Inverse Graphics with Large Language Models
Transactions on Machine Learning Research, August 2024 (article)
ei
Chen*, W., Horwood*, J., Heo, J., Hernández-Lobato, J. M.
Leveraging Task Structures for Improved Identifiability in Neural Network Representations
Transactions on Machine Learning Research, August 2024, *equal contribution (article)
hi
Khojasteh, B., Solowjow, F., Trimpe, S., Kuchenbecker, K. J.
Multimodal Multi-User Surface Recognition with the Kernel Two-Sample Test
IEEE Transactions on Automation Science and Engineering, 21(3):4432-4447, July 2024 (article)
ei
lds
Kladny, K., Kügelgen, J. V., Schölkopf, B., Muehlebach, M.
Deep Backtracking Counterfactuals for Causally Compliant Explanations
Transactions on Machine Learning Research, July 2024 (article)
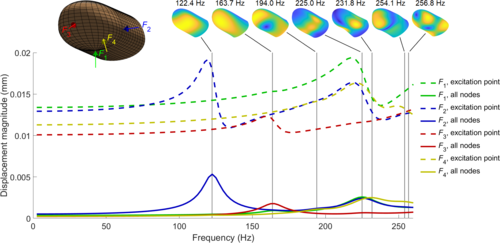
hi
Serhat, G., Kuchenbecker, K. J.
Fingertip Dynamic Response Simulated Across Excitation Points and Frequencies
Biomechanics and Modeling in Mechanobiology, 23, pages: 1369-1376, May 2024 (article)
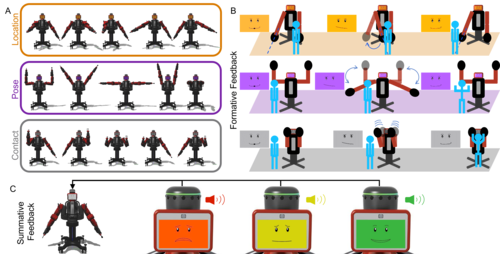
hi
Mohan, M., Nunez, C. M., Kuchenbecker, K. J.
Closing the Loop in Minimally Supervised Human-Robot Interaction: Formative and Summative Feedback
Scientific Reports, 14(10564):1-18, May 2024 (article)
ei
Schölkopf, B.
Grundfragen der künstlichen Intelligenz
astronomie - Das Magazin, 42, May 2024 (article)
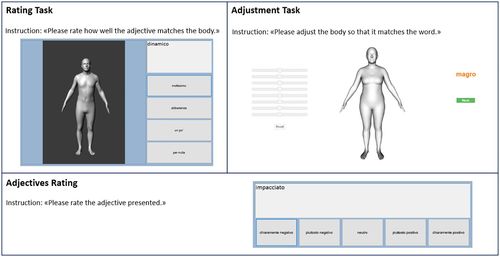
ps
Meneguzzo, P., Behrens, S. C., Pavan, C., Toffanin, T., Quiros-Ramirez, M. A., Black, M. J., Giel, K., Tenconi, E., Favaro, A.
Exploring Weight Bias and Negative Self-Evaluation in Patients with Mood Disorders: Insights from the BodyTalk Project,
Frontiers in Psychiatry, 15, Sec. Psychopathology, May 2024 (article)

ps
Li, C., Mellbin, Y., Krogager, J., Polikovsky, S., Holmberg, M., Ghorbani, N., Black, M. J., Kjellström, H., Zuffi, S., Hernlund, E.
The Poses for Equine Research Dataset (PFERD)
Nature Scientific Data, 11, May 2024 (article)
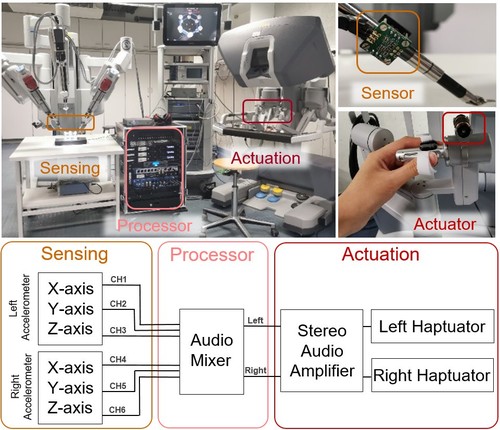
hi
Gong, Y., Mat Husin, H., Erol, E., Ortenzi, V., Kuchenbecker, K. J.
AiroTouch: Enhancing Telerobotic Assembly through Naturalistic Haptic Feedback of Tool Vibrations
Frontiers in Robotics and AI, 11(1355205):1-15, May 2024 (article)
ei
Zabel, S., Hennig, P., Nieselt, K.
VIPurPCA: Visualizing and Propagating Uncertainty in Principal Component Analysis
IEEE Transactions on Visualization and Computer Graphics, 30(4):2011-2022, April 2024 (article)
sf
Yasar, A. G., Chong, A., Dong, E., Gilbert, T., Hladikova, S., Mougan, C., Shen, X., Singh, S., Stoica, A., Thais, S.
Integration of Generative AI in the Digital Markets Act: Contestability and Fairness from a Cross-Disciplinary Perspective
LSE Legal Studies Working Paper, March 2024 (article)
hi
Allemang–Trivalle, A., Donjat, J., Bechu, G., Coppin, G., Chollet, M., Klaproth, O. W., Mitschke, A., Schirrmann, A., Cao, C. G. L.
Modeling Fatigue in Manual and Robot-Assisted Work for Operator 5.0
IISE Transactions on Occupational Ergonomics and Human Factors, 12(1-2):135-147, March 2024 (article)
ei
Mancini, M., Naeem, M. F., Xian, Y., Akata, Z.
Learning Graph Embeddings for Open World Compositional Zero-Shot Learning
IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(3):1545-1560, IEEE, New York, NY, March 2024 (article)
re
Lieder, F., Chen, P., Prentice, M., Amo, V., Tošić, M.
A mathematical principle for the gamification of behavior change
JMIR Serious Games , 12, JMIR Publications, March 2024 (article)

hi
Rokhmanova, N., Pearl, O., Kuchenbecker, K. J., Halilaj, E.
IMU-Based Kinematics Estimation Accuracy Affects Gait Retraining Using Vibrotactile Cues
IEEE Transactions on Neural Systems and Rehabilitation Engineering, 32, pages: 1005-1012, February 2024 (article)
ei
Visonà, G., Bouzigon, E., Demenais, F., Schweikert, G.
Network propagation for GWAS analysis: a practical guide to leveraging molecular networks for disease gene discovery
Briefings in Bioinformatics, 25(2), February 2024 (article)
ei
Pals, M., Macke, J. H., Barak, O.
Trained recurrent neural networks develop phase-locked limit cycles in a working memory task
PLOS Computational Biology, 20(2), February 2024 (article)
ei
Peisen, F., Gerken, A., Dahm, I., Nikolaou, K., Eigentler, T., Amaral, T., Moltz, J. H., Othman, A. E., Gatidis, S.
Pre-treatment 18F-FDG-PET/CT parameters as biomarkers for progression free survival, best overall response and overall survival in metastatic melanoma patients undergoing first-line immunotherapy
PLOS ONE, 19(1), January 2024 (article)
ei
Villar, S., Hogg, D. W., Yao, W., Kevrekidis, G. A., Schölkopf, B.
Towards fully covariant machine learning
Transactions on Machine Learning Research, January 2024 (article)
hi
Fitter, N. T., Mohan, M., Preston, R. C., Johnson, M. J., Kuchenbecker, K. J.
How Should Robots Exercise with People? Robot-Mediated Exergames Win with Music, Social Analogues, and Gameplay Clarity
Frontiers in Robotics and AI, 10(1155837):1-18, January 2024 (article)
hi
Khojasteh, B., Shao, Y., Kuchenbecker, K. J.
Robust Surface Recognition with the Maximum Mean Discrepancy: Degrading Haptic-Auditory Signals through Bandwidth and Noise
IEEE Transactions on Haptics, 17(1):58-65, January 2024, Presented at the IEEE Haptics Symposium (article)
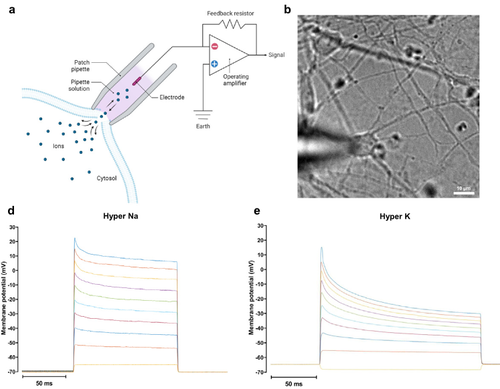
pi
Werneck, L., Han, M., Yildiz, E., Keip, M., Sitti, M., Ortiz, M.
A simple quantitative model of neuromodulation, Part I: Ion flow through neural ion channels
Journal of the Mechanics and Physics of Solids, 182, pages: 105457, 2024 (article)

zwe-ms
pi
Jelena Lazovic, E. G. A. W. P. S. A. S. J. L. G. W. M. S.
Nanodiamond-Enhanced Magnetic Resonance Imaging
Advanced Materials, 36(11):2310109, 2024 (article)
lds
Zughaibi, J., Nelson, B. J., Muehlebach, M.
Balancing a 3D Inverted Pendulum using Remote Magnetic Manipulation
Robotics and Automation Letters, 2024 (article) In revision
mms
Oh, H., Tumanov, N., Ban, V., Li, X., Richter, B., Hudson, M. R., Brown, C. M., Iles, G. N., Wallacher, D., Jorgensen, S. W., Daemen, L., Balderas-Xicohténcatl, R., Cheng, Y., Ramirez-Cuesta, A. J., Heere, M., Posada-Pérez, S., Hautier, G., Hirscher, M., Jensen, T. R., Filinchuk, Y.
Small-pore hydridic frameworks store densely packed hydrogen
Nature Chemistry, 16(5):809-816, Nature Publishing Group, London, UK, 2024 (article)

zwe-csfm
Gorke, O., Stuhlmüller, M., Tovar, G. E. M., Southan, A.
Unravelling parameter interactions in calcium alginate/polyacrylamide double network hydrogels using a design of experiments approach for the optimization of mechanical properties
Materials Advances, 5, pages: 2851-2859, Royal Society of Chemistry, 2024 (article)
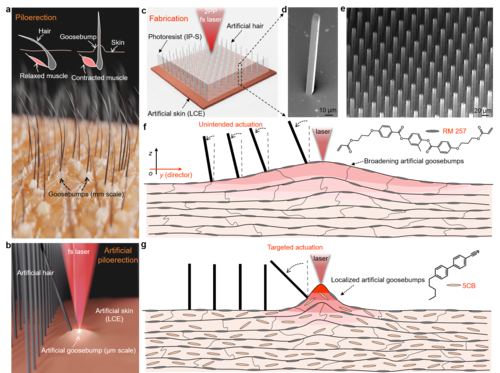
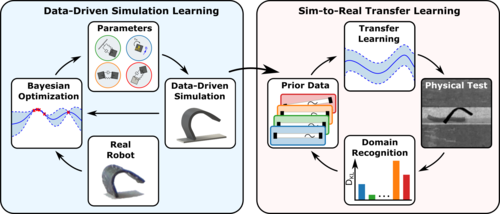
pi
Demir, S. O., Tiryaki, M. E., Karacakol, A. C., Sitti, M.
Learning Soft Millirobot Multimodal Locomotion with Sim-to-Real Transfer
Advanced Science, 2024 (article)
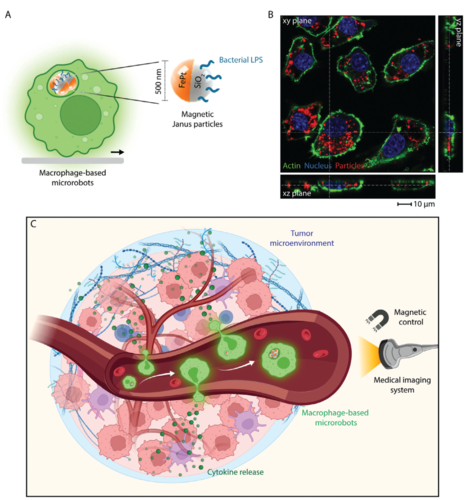
pi
Dogan, N. O., Suadiye, E., Wrede, P., Lazovic, J., Dayan, C. B., Soon, R. H., Aghakhani, A., Richter, G., Sitti, M.
Immune Cell‐Based Microrobots for Remote Magnetic Actuation, Antitumor Activity, and Medical Imaging
Advanced Healthcare Materials, pages: 2400711, 2024 (article)
lds
Florian Dörfler, Zhiyu He, Giuseppe Belgioioso, Saverio Bolognani, John Lygeros, Michael Muehlebach
Towards a systems theory of algorithms
IEEE Control System Letters, 2024 (article)
mms
Gallardo, R., Weigand, M., Schultheiss, K., Kakay, A., Mattheis, R., Raabe, J., Schütz, G., Deac, A., Lindner, J., Wintz, S.
Coherent magnons with giant nonreciprocity at nanoscale wavelengths
ACS Nano, 18(7):5249-5257, American Chemical Society, Washington, DC, 2024 (article)
mms
Balcerzak, M., Ponsoni, J. B., Petersen, H., Menéndez, C., Ternieden, J., Zhang, L., Winkelmann, F., Aguey-Zinsou, K., Hirscher, M., Felderhoff, M.
Hydrogen-stabilized ScYNdGd medium-entropy alloy for hydrogen storage
Journal of the American Chemical Society, 146(8):5283-5294, American Chemical Society, Washington, DC, 2024 (article)
al
Simon, A., Weimar, J., Martius, G., Oettel, M.
Machine learning of a density functional for anisotropic patchy particles
Journal of Chemical Theory and Computation, 2024 (article)
ei
Gebhard, T. D., Angerhausen, D., Konrad, B. S., Alei, E., Quanz, S. P., Schölkopf, B.
Parameterizing pressure-temperature profiles of exoplanet atmospheres with neural networks
Astronomy & Astrophysics, 681, 2024 (article)
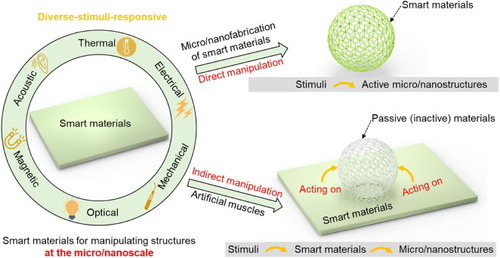
pi
Zhang, M., Sitti, M.
Perspective on smart materials for empowering small-scale manipulation
Science Bulletin, 69(6):718-721, 2024 (article)
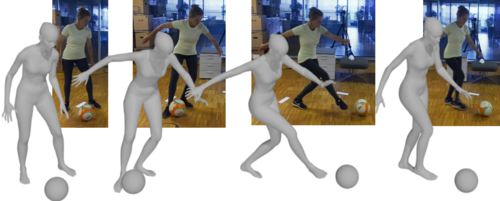
ps
Huang, Y., Taheri, O., Black, M. J., Tzionas, D.
InterCap: Joint Markerless 3D Tracking of Humans and Objects in Interaction from Multi-view RGB-D Images
International Journal of Computer Vision (IJCV), 2024 (article)