Reinforcement Learning and Control
Model-based Reinforcement Learning and Planning
Object-centric Self-supervised Reinforcement Learning
Self-exploration of Behavior
Causal Reasoning in RL
Equation Learner for Extrapolation and Control
Intrinsically Motivated Hierarchical Learner
Regularity as Intrinsic Reward for Free Play
Curious Exploration via Structured World Models Yields Zero-Shot Object Manipulation
Natural and Robust Walking from Generic Rewards
Goal-conditioned Offline Planning
Offline Diversity Under Imitation Constraints
Learning Diverse Skills for Local Navigation
Learning Agile Skills via Adversarial Imitation of Rough Partial Demonstrations
Combinatorial Optimization as a Layer / Blackbox Differentiation
Object-centric Self-supervised Reinforcement Learning
Symbolic Regression and Equation Learning
Representation Learning
Stepsize adaptation for stochastic optimization
Probabilistic Neural Networks
Learning with 3D rotations: A hitchhiker’s guide to SO(3)
Controller Learning using Bayesian Optimization
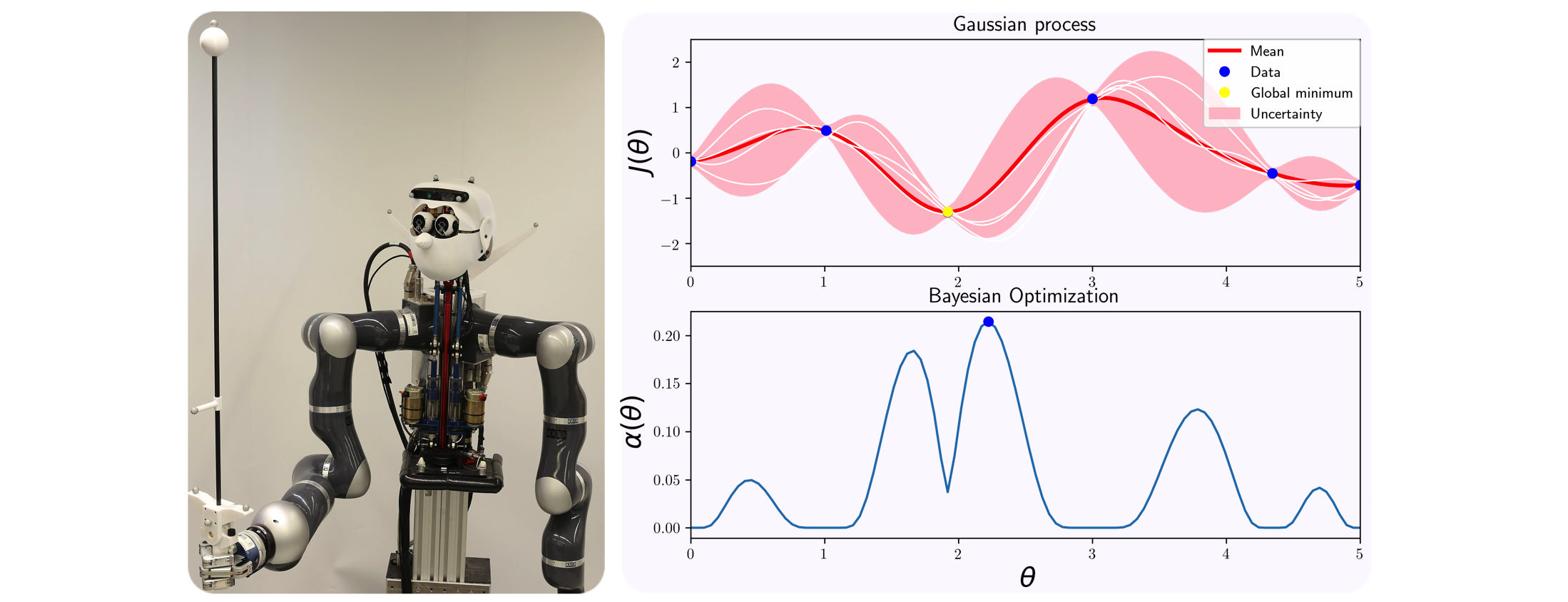
Autonomous systems such as humanoid robots are characterized by a multitude of feedback control loops operating at different hierarchical levels and time-scales. Designing and tuning these controllers typically requires significant manual modeling and design effort and exhaustive experimental testing. For managing the ever greater complexity and striving for greater autonomy, it is desirable to tailor intelligent algorithms that allow autonomous systems to learn from experimental data. In our research, we leverage automatic control theory, machine learning, and optimization to develop automatic control design and tuning algorithms.
In [![]()
![]()
![]() ], we propose a framework where an initial controller is automatically improved based on observed performance from a limited number of experiments. Entropy Search (ES) [
], we propose a framework where an initial controller is automatically improved based on observed performance from a limited number of experiments. Entropy Search (ES) [![]() ] serves as the underlying Bayesian optimizer for the auto-tuning method. It represents the latent control objective as a Gaussian process (GP) (see above figure) and sequentially suggests those controllers that are most informative about the location of the optimum. We validate the developed approaches on the experimental platforms at our institute (see figure).
] serves as the underlying Bayesian optimizer for the auto-tuning method. It represents the latent control objective as a Gaussian process (GP) (see above figure) and sequentially suggests those controllers that are most informative about the location of the optimum. We validate the developed approaches on the experimental platforms at our institute (see figure).
We have extended this framework into different directions to further improve data efficiency. When auto-tuning real complex systems (like humanoid robots), simulations of the system dynamics are typically available. They provide less accurate information than real experiments, but at a cheaper cost. Under limited experimental cost budget (i.e., experiment total time), our work [![]() ] extends ES to include the simulator as an additional information source and automatically trade off information vs. cost.
] extends ES to include the simulator as an additional information source and automatically trade off information vs. cost.
The aforementioned auto-tuning methods model the performance objective using standard GP models, typically agnostic to the control problem. In [![]() ], the covariance function of the GP model is tailored to the control problem at hand by incorporating its mathematical structure into the kernel design. In this way, unforeseen observations of the objective are predicted more accurately. This ultimately speeds up the convergence of the Bayesian optimizer.
], the covariance function of the GP model is tailored to the control problem at hand by incorporating its mathematical structure into the kernel design. In this way, unforeseen observations of the objective are predicted more accurately. This ultimately speeds up the convergence of the Bayesian optimizer.
Bayesian optimization provides a powerful framework for controller learning, which we have successfully applied on very different settings: humanoid robots [![]() ], micro robots [
], micro robots [![]() ] and automotive industry [
] and automotive industry [![]() ].
].
Members






Publications