Reinforcement Learning and Control
Model-based Reinforcement Learning and Planning
Object-centric Self-supervised Reinforcement Learning
Self-exploration of Behavior
Causal Reasoning in RL
Equation Learner for Extrapolation and Control
Intrinsically Motivated Hierarchical Learner
Regularity as Intrinsic Reward for Free Play
Curious Exploration via Structured World Models Yields Zero-Shot Object Manipulation
Natural and Robust Walking from Generic Rewards
Goal-conditioned Offline Planning
Offline Diversity Under Imitation Constraints
Learning Diverse Skills for Local Navigation
Learning Agile Skills via Adversarial Imitation of Rough Partial Demonstrations
Combinatorial Optimization as a Layer / Blackbox Differentiation
Object-centric Self-supervised Reinforcement Learning
Symbolic Regression and Equation Learning
Representation Learning
Stepsize adaptation for stochastic optimization
Probabilistic Neural Networks
Learning with 3D rotations: A hitchhiker’s guide to SO(3)
Dual-Force: Enhanced Offline Diversity Maximization under Imitation Constraints
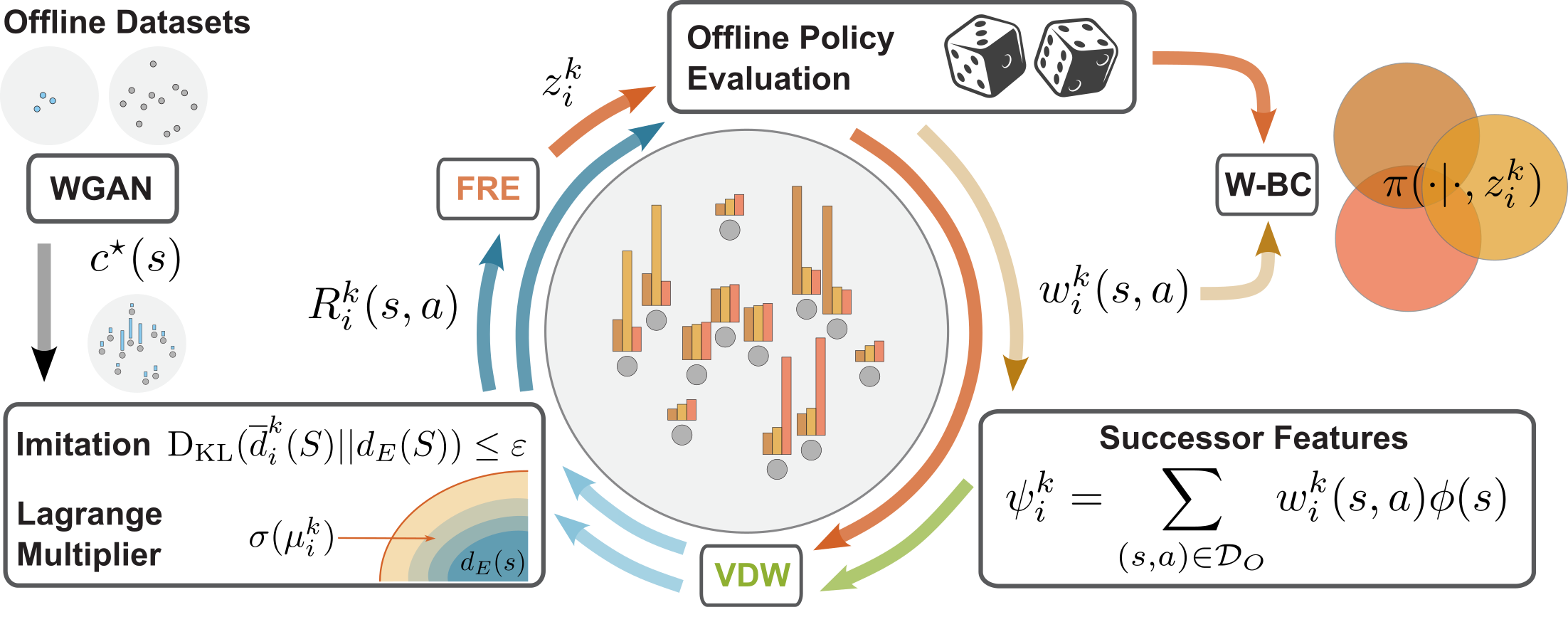
While many algorithms for diversity maximization under imitation constraints are online in nature, many applications require offline algorithms without environment interactions. Tackling this problem in the offline setting, however, presents significant challenges that require non-trivial, multi-stage optimization processes with non-stationary rewards. In this work, we present a novel offline algorithm that enhances diversity using an objective based on Van der Waals (VdW) force and successor features, and eliminates the need to learn a previously used skill discriminator. Moreover, by conditioning the value function and policy on a pre-trained Functional Reward Encoding (FRE), our method allows for better handling of nonstationary rewards and provides zero-shot recall of all skills encountered during training, significantly expanding the set of skills learned in prior work. Consequently, our algorithm benefits from receiving a consistently strong diversity signal (VdW), and enjoys more stable and efficient training. We demonstrate the effectiveness of our method in generating diverse skills for two robotic tasks in simulation: locomotion of a quadruped and local navigation with obstacle traversal.
Members


Publications