Reinforcement Learning and Control
Model-based Reinforcement Learning and Planning
Object-centric Self-supervised Reinforcement Learning
Self-exploration of Behavior
Causal Reasoning in RL
Equation Learner for Extrapolation and Control
Intrinsically Motivated Hierarchical Learner
Regularity as Intrinsic Reward for Free Play
Curious Exploration via Structured World Models Yields Zero-Shot Object Manipulation
Natural and Robust Walking from Generic Rewards
Goal-conditioned Offline Planning
Offline Diversity Under Imitation Constraints
Learning Diverse Skills for Local Navigation
Learning Agile Skills via Adversarial Imitation of Rough Partial Demonstrations
Combinatorial Optimization as a Layer / Blackbox Differentiation
Object-centric Self-supervised Reinforcement Learning
Symbolic Regression and Equation Learning
Representation Learning
Stepsize adaptation for stochastic optimization
Probabilistic Neural Networks
Learning with 3D rotations: A hitchhiker’s guide to SO(3)
Language and Movement
Understanding human behavior requires more than 3D pose. It requires capturing the semantics of human movement — what a person is doing, how they’re doing it, and why. The what and why of human movement — the actions of a person, their goals, emotions, and mental states — are typically described via natural language. Thus, grounding human movement in language, is a key to modeling and synthesizing human behavior.
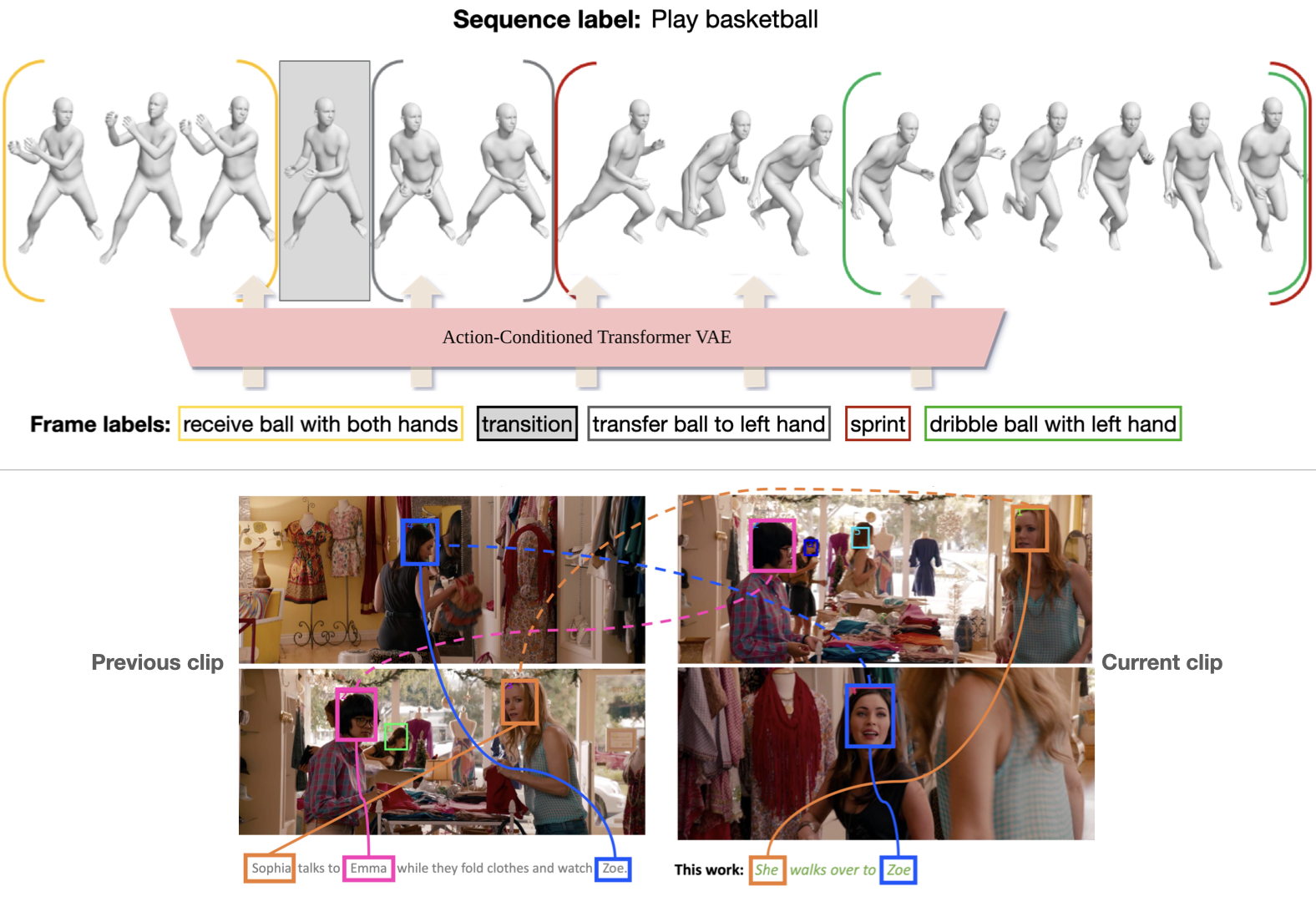
Progress in this requires 3D movement data that is precisely aligned with action descriptions. In BABEL [![]() ] we label (>250) actions performed in (>43 hours) mocap sequences from AMASS [
] we label (>250) actions performed in (>43 hours) mocap sequences from AMASS [![]() ]. Fine-grained "frame labels" precisely capture the duration of each action in a sequence. BABEL is being leveraged for tasks like action recognition, temporal action localization, and motion synthesis.
]. Fine-grained "frame labels" precisely capture the duration of each action in a sequence. BABEL is being leveraged for tasks like action recognition, temporal action localization, and motion synthesis.
Since 3D mocap data will always be limited, we would like to learn language-grounded movement from video. Our approach identifies individual actors in a movie clip and synthesizes language descriptions of their actions and interactions [![]() ]. The approach first localizes characters by relating their visual appearance to mentions in the movie scripts via a semi-supervised approach. This (noisy) supervision greatly improves the performance of a description model.
]. The approach first localizes characters by relating their visual appearance to mentions in the movie scripts via a semi-supervised approach. This (noisy) supervision greatly improves the performance of a description model.
ACTOR [![]() ] is an example of our work on synthesizing human movement, conditioned on action labels. Despite being trained with noisy data estimated from monocular video, ACTOR's transformer VAE architecture learns to synthesize diverse and realistic movements of varied length.
] is an example of our work on synthesizing human movement, conditioned on action labels. Despite being trained with noisy data estimated from monocular video, ACTOR's transformer VAE architecture learns to synthesize diverse and realistic movements of varied length.
Members







Publications