Human Pose, Shape and Action
3D Pose from Images
2D Pose from Images
Beyond Motion Capture
Action and Behavior
Body Perception
Body Applications
Pose and Motion Priors
Clothing Models (2011-2015)
Reflectance Filtering
Learning on Manifolds
Markerless Animal Motion Capture
Multi-Camera Capture
2D Pose from Optical Flow
Body Perception
Neural Prosthetics and Decoding
Part-based Body Models
Intrinsic Depth
Lie Bodies
Layers, Time and Segmentation
Understanding Action Recognition (JHMDB)
Intrinsic Video
Intrinsic Images
Action Recognition with Tracking
Neural Control of Grasping
Flowing Puppets
Faces
Deformable Structures
Model-based Anthropometry
Modeling 3D Human Breathing
Optical flow in the LGN
FlowCap
Smooth Loops from Unconstrained Video
PCA Flow
Efficient and Scalable Inference
Motion Blur in Layers
Facade Segmentation
Smooth Metric Learning
Robust PCA
3D Recognition
Object Detection
EMAGE: Full-body Gestures from Audio
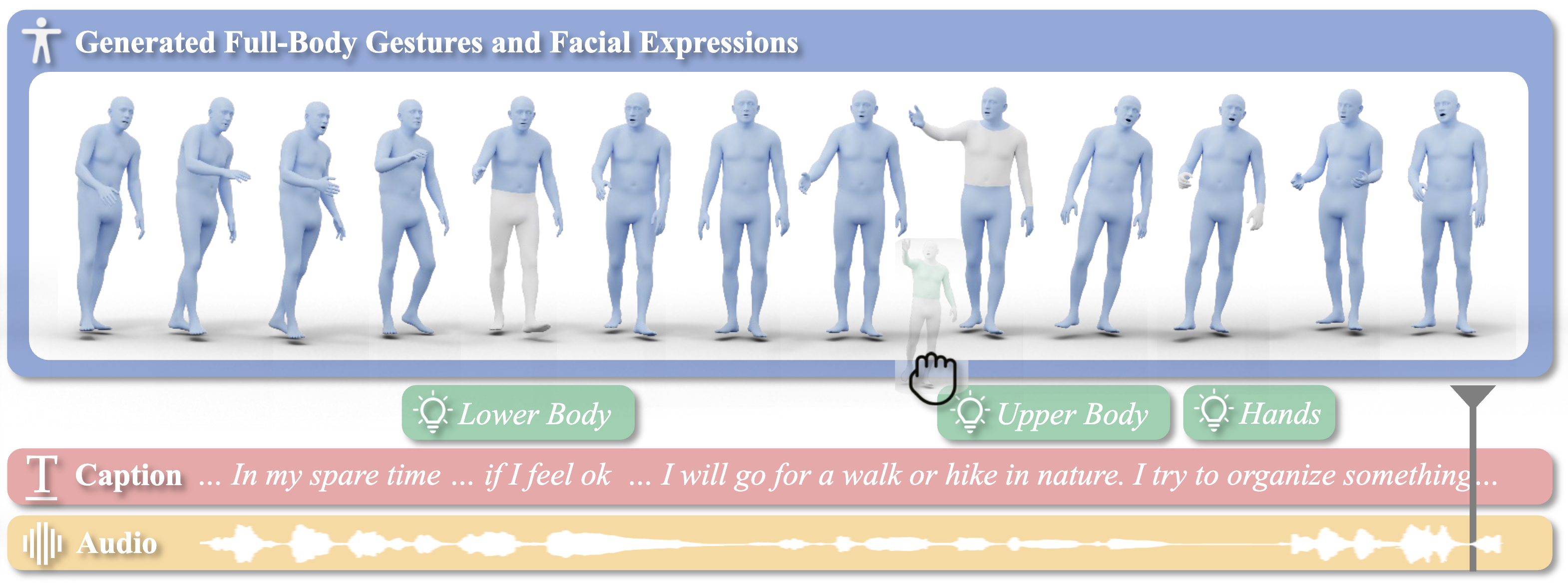
We propose EMAGE, a framework to generate full-body human gestures from audio and masked gestures, encompassing facial, local body, hands, and global movements. To achieve this, we first introduce BEAT2 (BEAT-SMPLX-FLAME), a new mesh-level holistic co-speech dataset. BEAT2 combines a MoShed SMPL-X body with FLAME head parameters and further refines the modeling of head, neck, and finger movements, offering a community-standardized, high-quality 3D motion captured dataset. EMAGE leverages masked body gesture priors during training to boost inference performance. It involves a Masked Audio Gesture Transformer, facilitating joint training on audio-to-gesture generation and masked gesture reconstruction to effectively encode audio and body gesture hints. Encoded body hints from masked gestures are then separately employed to generate facial and body movements. Moreover, EMAGE adaptively merges speech features from the audio’s rhythm and content and utilizes four compositional VQ-VAEs to enhance the results’ fidelity and diversity. Experiments demonstrate that EMAGE generates holistic gestures with state-of-the-art performance and is flexible in accepting predefined spatial-temporal gesture inputs, generating complete, audio-synchronized results. Our code and dataset are available.

Members


Publications