Human Pose, Shape and Action
3D Pose from Images
2D Pose from Images
Beyond Motion Capture
Action and Behavior
Body Perception
Body Applications
Pose and Motion Priors
Clothing Models (2011-2015)
Reflectance Filtering
Learning on Manifolds
Markerless Animal Motion Capture
Multi-Camera Capture
2D Pose from Optical Flow
Body Perception
Neural Prosthetics and Decoding
Part-based Body Models
Intrinsic Depth
Lie Bodies
Layers, Time and Segmentation
Understanding Action Recognition (JHMDB)
Intrinsic Video
Intrinsic Images
Action Recognition with Tracking
Neural Control of Grasping
Flowing Puppets
Faces
Deformable Structures
Model-based Anthropometry
Modeling 3D Human Breathing
Optical flow in the LGN
FlowCap
Smooth Loops from Unconstrained Video
PCA Flow
Efficient and Scalable Inference
Motion Blur in Layers
Facade Segmentation
Smooth Metric Learning
Robust PCA
3D Recognition
Object Detection
Language, Vision, and World Models
Can we leverage large language models (LLMs) to teach computer to see? How much do multi-modal vision-language models (VLMs) really understand about the 3D world and how it works?
We were using language to help solve vision problems well before LLMs arrived. For example, SHAPY [![]() ] leverages textual descriptions of human body shape as a form of side information to train a model to estimate metrically accurate 3D human body shape. BARC [
] leverages textual descriptions of human body shape as a form of side information to train a model to estimate metrically accurate 3D human body shape. BARC [![]() ] uses dog breed information to learn 3D dog shapes from 2D images; dogs of the same breed should have more similar shapes than dogs of different breeds. But our use of language is much richer than this.
] uses dog breed information to learn 3D dog shapes from 2D images; dogs of the same breed should have more similar shapes than dogs of different breeds. But our use of language is much richer than this.
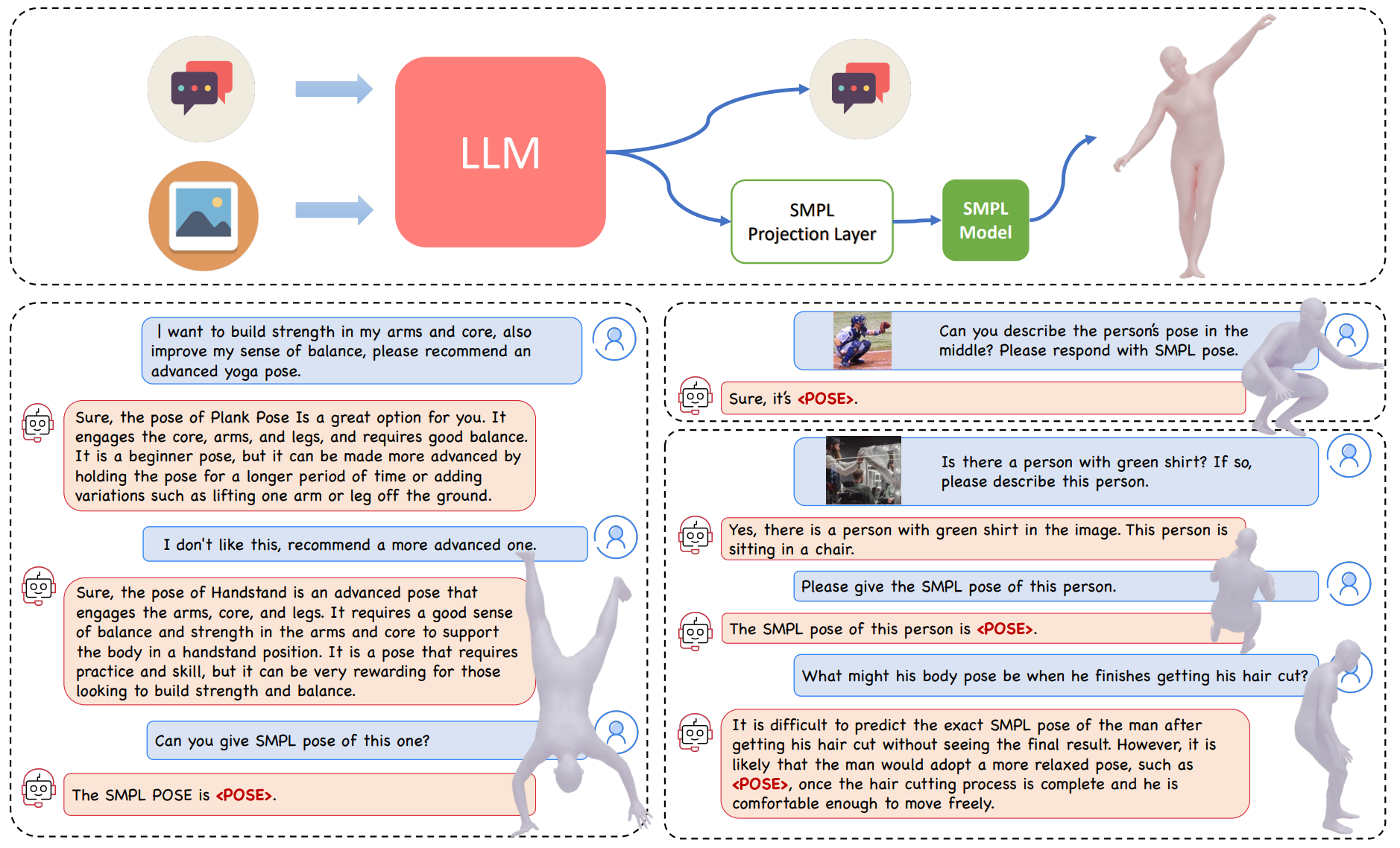
Human pose: Traditional 3D human pose estimation involves regressing pose parameters from pixels. With ChatPose [![]() ], we take a different approach and fine tune a VLM to reason about human pose given an image or text. When asked about 3D pose, ChatPose outputs a special token, the embedding of which is converted to continuous pose parameters by an MLP. ChatPose can infer human poses by exploiting its general knowledge of humans, opening an entirely new avenue for research on 3D human pose estimation and understanding.
], we take a different approach and fine tune a VLM to reason about human pose given an image or text. When asked about 3D pose, ChatPose outputs a special token, the embedding of which is converted to continuous pose parameters by an MLP. ChatPose can infer human poses by exploiting its general knowledge of humans, opening an entirely new avenue for research on 3D human pose estimation and understanding.
3D scenes: The classical problem of inverse graphics involves converting a 2D image into 3D graphics primitives. Instead of the classical ``analysis by synthesis" approach, we fine-tune an LLM to take an image and output a structured, compositional 3D-scene representation (i.e.~Blender code) [![]() ]. We introduce a continuous numeric head, which is critical for 3D reasoning. We find that LLMs can perform inverse graphics through next-token prediction, without classical photometric supervision.
]. We introduce a continuous numeric head, which is critical for 3D reasoning. We find that LLMs can perform inverse graphics through next-token prediction, without classical photometric supervision.
Video diffusion models go further and are able to generate realistic videos given an image or text as input. To do so, they must have a latent representation of the 3D world that we can exploit to solve tasks in computer vision. To explore this, we propose the task of bounded video generation, which requires generating all the video frames between a start and end frame. Using a frozen video diffusion model, we introduce a new Time Reversal Fusion sampling strategy, that fuses the temporally forward and backward denoising paths conditioned on the start and end frame [![]() ]. We find video models are able to infer in-between frames that are consistent with rigid and articulated scenes.
]. We find video models are able to infer in-between frames that are consistent with rigid and articulated scenes.