Human Pose, Shape and Action
3D Pose from Images
2D Pose from Images
Beyond Motion Capture
Action and Behavior
Body Perception
Body Applications
Pose and Motion Priors
Clothing Models (2011-2015)
Reflectance Filtering
Learning on Manifolds
Markerless Animal Motion Capture
Multi-Camera Capture
2D Pose from Optical Flow
Body Perception
Neural Prosthetics and Decoding
Part-based Body Models
Intrinsic Depth
Lie Bodies
Layers, Time and Segmentation
Understanding Action Recognition (JHMDB)
Intrinsic Video
Intrinsic Images
Action Recognition with Tracking
Neural Control of Grasping
Flowing Puppets
Faces
Deformable Structures
Model-based Anthropometry
Modeling 3D Human Breathing
Optical flow in the LGN
FlowCap
Smooth Loops from Unconstrained Video
PCA Flow
Efficient and Scalable Inference
Motion Blur in Layers
Facade Segmentation
Smooth Metric Learning
Robust PCA
3D Recognition
Object Detection
Inferring and exploiting contact
Humans use touch to interact with each other and the world. While we use our hands and feet to support grasping and locomotion, we also leverage our entire body surface in our daily
interactions with the objects. We great, comfort, and bond with each other though touch. To fully model human behavior, we must be able to capture, generate and understand human-human, human-object, and human-scene contact. To enable this, we have created numerous datasets including ARCTIC, INTERCAP, DAMON, HOT, RICH and Flickr Fits; see the Dataset Research Field for details.
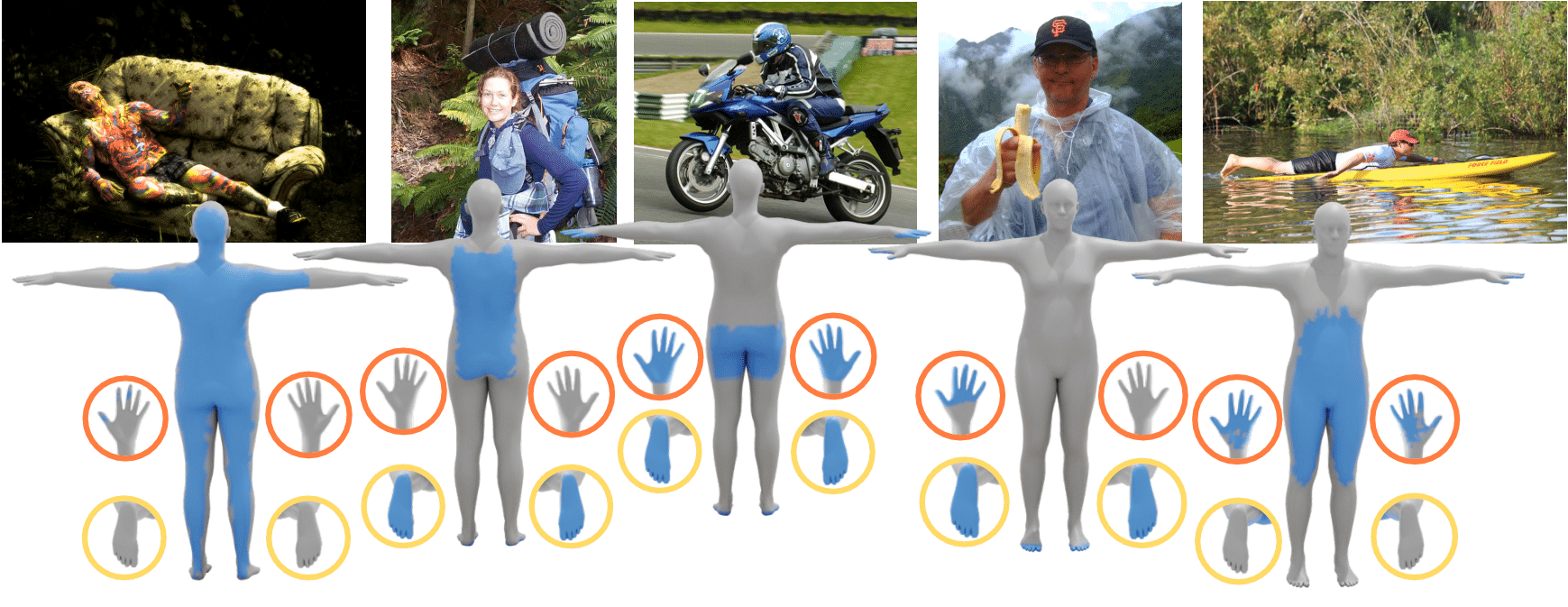
Contact estimation: We have pioneered the inference of 3D contact from images. Using RICH, we trained BSTRO [![]() ], which predicts dense body-scene contacts from an RGB image. Our key insight is that regions in contact are always occluded so the network uses a transfomer to explore the whole image for evidence. Using DAMON, we trained DECO [
], which predicts dense body-scene contacts from an RGB image. Our key insight is that regions in contact are always occluded so the network uses a transfomer to explore the whole image for evidence. Using DAMON, we trained DECO [![]() ], a novel 3D contact detector that uses both body-part-driven and scene-context-driven attention to estimate vertex-level contact on the SMPL body.
], a novel 3D contact detector that uses both body-part-driven and scene-context-driven attention to estimate vertex-level contact on the SMPL body.
Contact and capture: Given a video sequence, MOVER [![]() ] estimates both the 3D objects and human movement in the scene such that the object and human are consistent. If a person is touching an object, they need to be in the same place. Likewise, the person and the object cannot occupy the same space. We also use LLMs to extract commonsense knowledge about human-object interaction and use this to reason in 3D about human-object interactions. HOLD [
] estimates both the 3D objects and human movement in the scene such that the object and human are consistent. If a person is touching an object, they need to be in the same place. Likewise, the person and the object cannot occupy the same space. We also use LLMs to extract commonsense knowledge about human-object interaction and use this to reason in 3D about human-object interactions. HOLD [![]() ] goes further to jointly reconstruct an interacting hand and object from a monocular video using a compositional articulated implicit model that disentangles the 3D hand and object from 2D images. Contact is also critical for support. With IPMAN [
] goes further to jointly reconstruct an interacting hand and object from a monocular video using a compositional articulated implicit model that disentangles the 3D hand and object from 2D images. Contact is also critical for support. With IPMAN [![]() ], we formulate intuitive-physics constraints that exploit contact to estimate the center of pressure, center of mass, and base of support and use these to estimate stable body poses from images. We also we exploit contact in estimating dog poses in BARC [
], we formulate intuitive-physics constraints that exploit contact to estimate the center of pressure, center of mass, and base of support and use these to estimate stable body poses from images. We also we exploit contact in estimating dog poses in BARC [![]() ][
][![]() ]. With dogs, there is little 3D training data, making pose inference hard. We exploit body-ground contact in estimating dog pose and find that it significantly improves results.
]. With dogs, there is little 3D training data, making pose inference hard. We exploit body-ground contact in estimating dog pose and find that it significantly improves results.
Contact generation: The way individuals position themselves in relation to others, ie.~proxemics, conveys social cues affecting the dynamics of social interaction. Using Flickr Fits, we learn the joint distribution over the 3D poses of two people in close social interaction with a novel denoising diffusion model called BUDDI [![]() ].
].