Human Pose, Shape and Action
3D Pose from Images
2D Pose from Images
Beyond Motion Capture
Action and Behavior
Body Perception
Body Applications
Pose and Motion Priors
Clothing Models (2011-2015)
Reflectance Filtering
Learning on Manifolds
Markerless Animal Motion Capture
Multi-Camera Capture
2D Pose from Optical Flow
Body Perception
Neural Prosthetics and Decoding
Part-based Body Models
Intrinsic Depth
Lie Bodies
Layers, Time and Segmentation
Understanding Action Recognition (JHMDB)
Intrinsic Video
Intrinsic Images
Action Recognition with Tracking
Neural Control of Grasping
Flowing Puppets
Faces
Deformable Structures
Model-based Anthropometry
Modeling 3D Human Breathing
Optical flow in the LGN
FlowCap
Smooth Loops from Unconstrained Video
PCA Flow
Efficient and Scalable Inference
Motion Blur in Layers
Facade Segmentation
Smooth Metric Learning
Robust PCA
3D Recognition
Object Detection
Action and Behavior
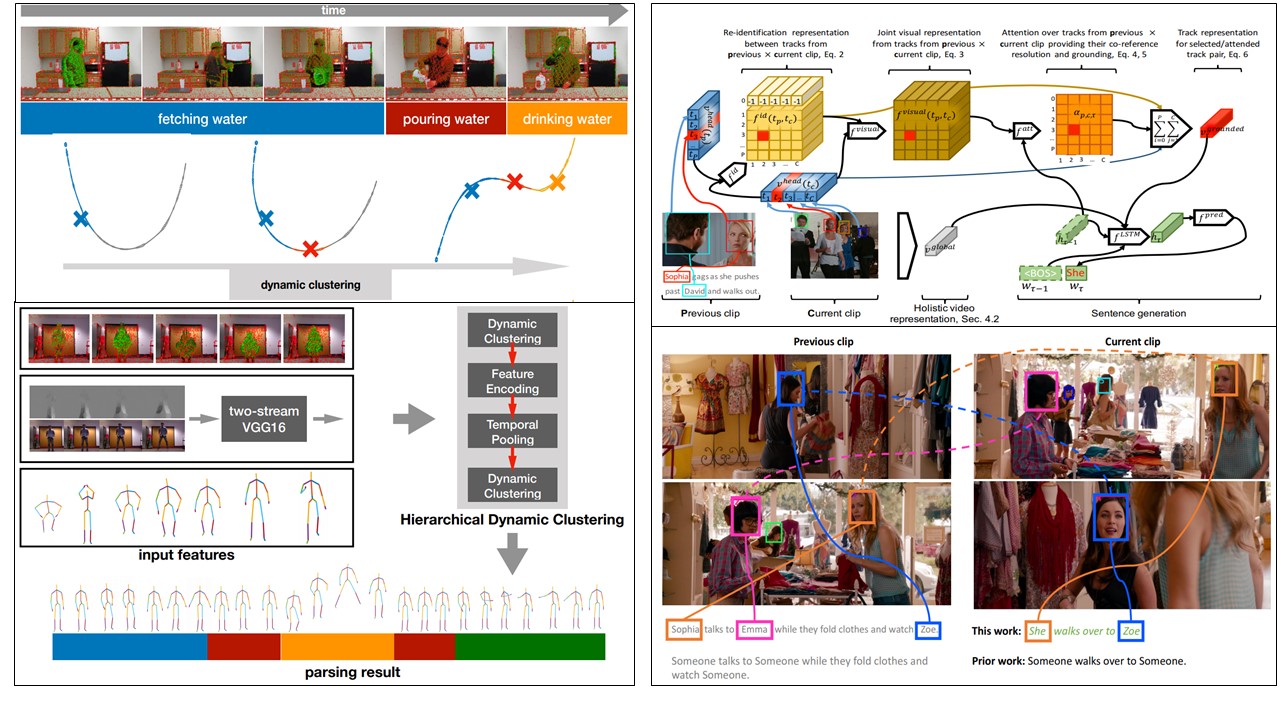
Human behavior can be described at multiple levels. At the lowest level, we observe the 3D pose of the body over time. Poses can be organized into primitives that capture coordinated activity of different body parts. These further form more complex "actions" or "behaviors". Finally, underlying all of the above are the goals, motives, and emotions of the person; that is, the cause of the movement. Our ultimate goal is to extract this high-level causal information from video.
Low-level understanding. Humans can readily differentiate biological motion from non-biological motion. They can do this from sparse visual cues like moving dots and without any explicit supervision. In this spirit, we perform behavior analysis at a low-level using a novel dynamic clustering algorithm that groups actions in an online fashion [![]() ]. As a building block, dynamic clustering is employed in a computational pipeline, where low-level visual cues are aggregated to high-level action patterns via temporal pooling. Our experiments show that this hierarchical dynamic clustering scheme is reliable, generic for diverse input features and fast.
]. As a building block, dynamic clustering is employed in a computational pipeline, where low-level visual cues are aggregated to high-level action patterns via temporal pooling. Our experiments show that this hierarchical dynamic clustering scheme is reliable, generic for diverse input features and fast.
High-level understanding. Here we relate low-level behavior to high-level concepts by identifying individual actors and synthesizing natural-language descriptions of their actions and interactions. We do so using weak supervision provided by scripts associated with the video. As a first attempt, we generate descriptions with grounded and co-referenced people [![]() ]. Specifically, we first learn to localize characters by relating their visual appearance to mentions in the descriptions via a semi-supervised approach. We then provide this (noisy) supervision to a description model, which greatly improves its performance. Our proposed description model improves over prior work w.r.t. generated description quality and additionally provides grounding and local co-reference resolution.
]. Specifically, we first learn to localize characters by relating their visual appearance to mentions in the descriptions via a semi-supervised approach. We then provide this (noisy) supervision to a description model, which greatly improves its performance. Our proposed description model improves over prior work w.r.t. generated description quality and additionally provides grounding and local co-reference resolution.
Ongoing work leverages richer models of the human body and its motion as well as richer models of the scene and the objects in it.
Members


Publications