Human Pose, Shape and Action
3D Pose from Images
2D Pose from Images
Beyond Motion Capture
Action and Behavior
Body Perception
Body Applications
Pose and Motion Priors
Clothing Models (2011-2015)
Reflectance Filtering
Learning on Manifolds
Markerless Animal Motion Capture
Multi-Camera Capture
2D Pose from Optical Flow
Body Perception
Neural Prosthetics and Decoding
Part-based Body Models
Intrinsic Depth
Lie Bodies
Layers, Time and Segmentation
Understanding Action Recognition (JHMDB)
Intrinsic Video
Intrinsic Images
Action Recognition with Tracking
Neural Control of Grasping
Flowing Puppets
Faces
Deformable Structures
Model-based Anthropometry
Modeling 3D Human Breathing
Optical flow in the LGN
FlowCap
Smooth Loops from Unconstrained Video
PCA Flow
Efficient and Scalable Inference
Motion Blur in Layers
Facade Segmentation
Smooth Metric Learning
Robust PCA
3D Recognition
Object Detection
AWOL: Analysis WithOut synthesis using Language
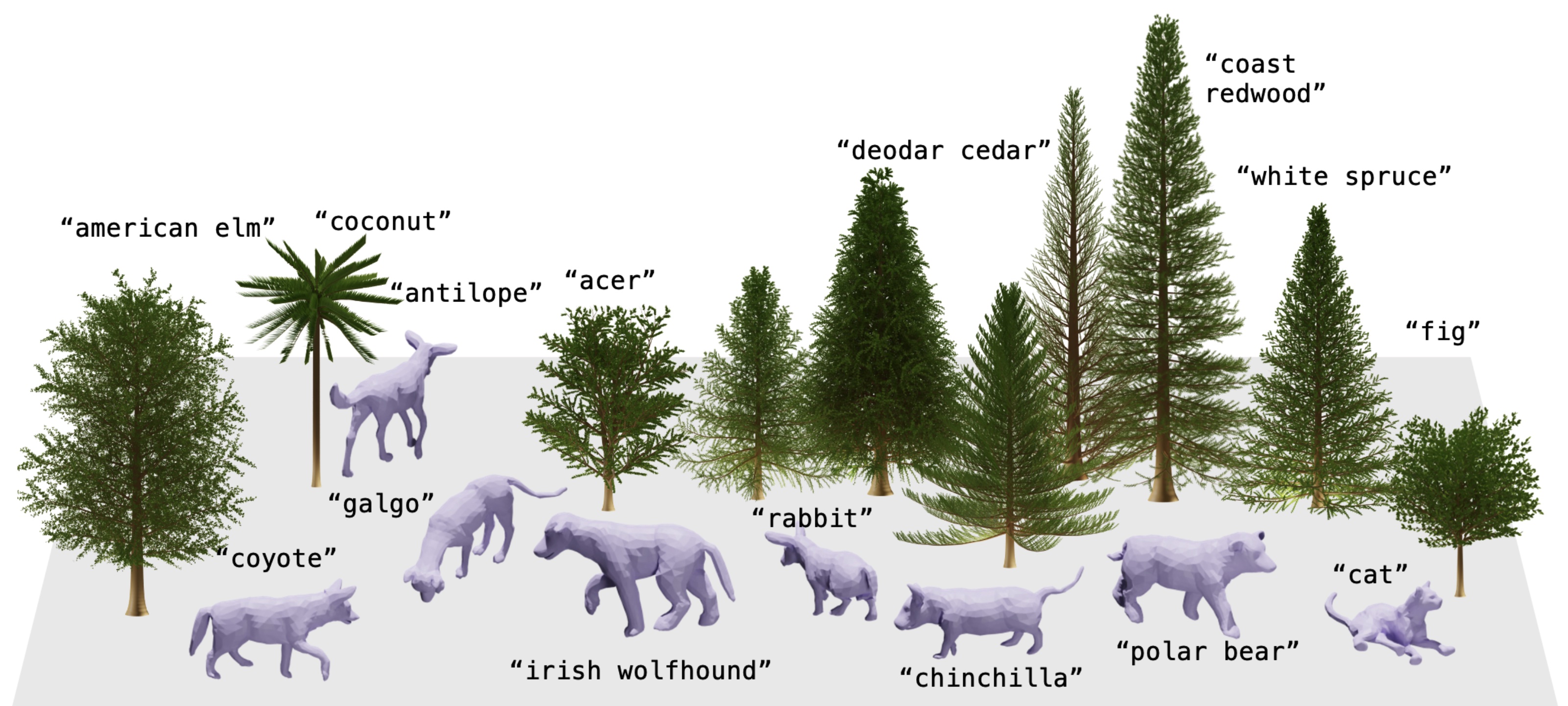
Many classical parametric 3D shape models exist, but creating novel shapes with such models requires expert knowledge of their parameters. For example, imagine creating a specific type of tree using procedural graphics or a new kind of animal from a statistical shape model. Our key idea is to leverage language to control such existing models to produce novel shapes. This involves learning a mapping between the latent space of a vision-language model and the parameter space of the 3D model, which we do using a small set of shape and text pairs. Our hypothesis is that mapping from language to parameters allows us to generate parameters for objects that were never seen during training. If the mapping between language and parameters is sufficiently smooth, then interpolation or generalization in language should translate appropriately into novel 3D shapes. We test our approach with two very different types of parametric shape models (quadrupeds and arboreal trees). We use a learned statistical shape model of quadrupeds and show that we can use text to generate new animals not present during training. In particular, we demonstrate state-of-the-art shape estimation of 3D dogs. This work also constitutes the first language-driven method for generating 3D trees. Finally, embedding images in the CLIP latent space enables us to generate animals and trees directly from images.

Members


Publications